![]()
We, as team Final Fantasy, had come into the course without any knowledge of codesign and JPEG encoding scheme, and was thrown into the digital design project of designing a JPEG encoder processor using codesign with FPGA and an 8-bit embedded processor. Right away we determined that the DCT will go on the FPGA, and the rest will go on the CPU, since we want to place the most time consuming section on FPGA. Once the decision was made about the partitioning, we never really took a look at other alternatives.
![]()
2. Design Goals/Summary of Architectural Features

As specified in the design goals, the team will be implementing a pipelined processor that will meet the major design goals of throughput via pipelined design. The illustration below shows the block diagrams for the pipelined flow, with the original image first fetched into the FPGA in blocks of 64 by 64 matrix. Each block will then go through row DCT(discreet cosine transform), transpose, column DCT, and then accumulation at the end of pipeline inside the FPGA. From there, the output of FPGA will go into the CPU where it will undergo the zig-zag operation and Huffman encoding scheme. The output of CPU will be the final output, which will be stored on a SRAM chip.
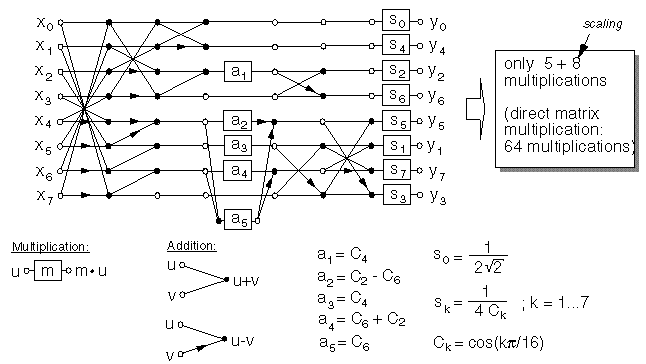
For the DCT implementation, we have decided to use the fast 1D-DCT algorithm by Arai, Agui and Nakajuma, which can integrate the quantization process in the last stage of DCT multiplication. This will cut down on the area and time that could have been spent on quantization alone. Since DCT is performed on 8 by 8 blocks, the 64 values from the DCT calculation will be stored in a SRAM used as accumulation buffer.
The minor design goals that we have chosen tie closely with the architecture that we chose. Because we are designing a pipelined processor, we will be going for speed. The second minor design goal of shared memory arises from the fact that the CPU will be accessing the output from the FPGA that is stored in a SRAM cell.
![]()
Different measurement strategies
will be used to obtain throughput for the CPU, throughput for the FPGA,
and the latency for the shared memory. For throughput measurements, extra
pins on the CPU and FPGA will be used to signal start and finish of the
process in the actual measurement. But we will also use Verilog calculations
from synthesis to get FPGA cycle counts, and use HiWare simulations to
obtain CPU cycle counts. With the final calculation, FPGA takes 1497 cycles
to process one 64-byte block from starting of fetching data until finishing
of writing to the intermediate memory. The cycle counts thereafter are
about 811 cycles per individual 64-byte block. As for the CPU, since each
64-byte block is different, the resulting cycle count will be different
for each block. The following chart shows statistics gathered for the first
six 64-byte blocks.
| Block | Including time to load the blocks into memory | Not including time to load blocks |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
It seems like loading a 64-byte block in the simulator would take 6074 cycles. With the handshaking protocol, the actually result that we get when running on the actual board should take a little more cycles. For the shared memory measurement, we will measure the latency between request and grant as both signals can be easily observed.
![]()
Since this is a team project, there obviously need to be a division of work among the team members to complete the project in a timely manner. In our case, Dong is the person in charge of the FPGA section with specialization in DCT implementation in Verilog. Salman, on the other hand, is the Motorola processor expert who is responsible for porting the original JPEG C code over to the embedded processor. Yen-Pang (Jeff) is the DIO specialist responsible for the DIO hardware and software interface. Last but not least, Chen-Li (Tom) is the team leader in charge of all communications, wire-wrappings, and shared memory implementation.
![]()
5. Performance Against Schedule
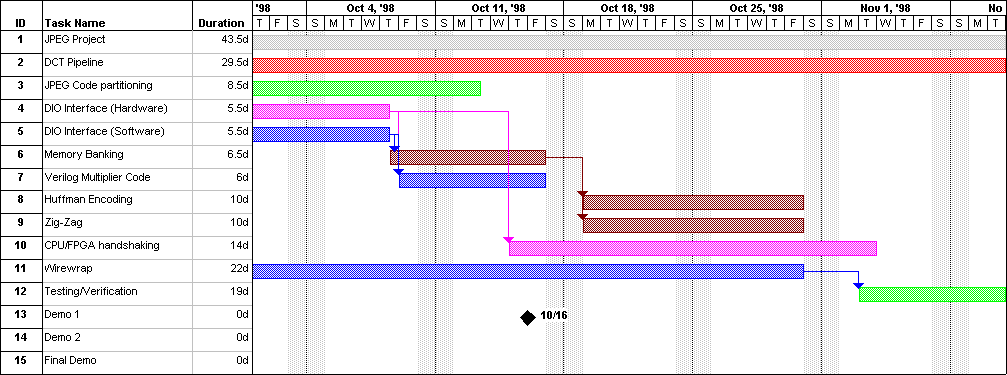
Overall, we actually finished the bulk of the project way ahead of the estimated time, which left us plenty of time to debug and make adjustments. We are a little behind in trying to get zig-zag and Huffman encoding to run on the CPU according to our internal schedule. Because we left more time for debugging and testing, we were able to make up for the lost time in the weeks after. By the end of the semester, we really appreciated having such an aggressive internal schedule as it gave us more time to adjust and improve upon the results.
![]()
In conjunction with implementation of the JPEG algorithm, the technical lessons learned with doing the project are of additional interest. Using codesign as the foundation, most of the technical details lie in the intricate details of the various pieces in the design -- i.e. the relative size and speed of the FPGA, the memory configuration of the embedded processor, and the precision needed to perform an adequate DCT. Indeed, these three technical aspects form the fundamental three parts of our design: the FPGA hardware, CPU software, and the actual JPEG algorithm.
As a pivotal aspect of our push for pipelining, the FPGA and the Verilog code provides the bulk of our architectural lessons. Coming into the project, not much was known as to what would actually fit onto the FPGA. After talking to students of the former 545 class, the plan focussed on getting the large multipliers to fit onto the FPGA. After a few experiments, however, the plan for fitting 4 multipliers evaporated as our hard efforts resulted in CLB usage of 15% per multiplier (12-bit with input/output registers). Due to the extra complexity of our state machine combined with extra fetch and accumulation pipelines, clearly the design was more space consuming than the original estimates. After a little more analysis, however, the back-of-the-envelope calculations showed that even with the lack of additional multipliers, the CPU lagged the FPGA in performance by a wide margin. For example, during the zig-zag stage of the JPEG algorithm, 64 bytes of DCT data must be obtained from the SRAM. If one does the quick calculation, 64 fetches from the CPU at 8 MHz and hundreds more to do a zig-zag will add up to be many more cycles than the FPGA needs to finish another 64 bytes of DCT data. This actually does not include the Huffman encoding!
So, the focus moves to the Motorola CPU. Due to the embedded nature of the design, one has to write custom memory management for the CPU. Consequently, digging through the obfuscate (and sometimes incorrect) documentation for the HC11, a method for banking the memory was derived. Originally, this banking method, after a few iterations of changes, finally worked for PCBug. When the HiWare monitor was released, however, it was decided that moving to the other tool would boost productivity substantially due to the extra support for single-stepping source code in hardware.
To the dismay of the team members involved, however, it was found that even though the configuration worked under PCBug, the HiWare monitor didn't work correctly. Additional time was spent changing the configuration to match the working test cases provided by the TA-- this ensured our hardware was correct. After this step, the team backtracked to the memory banking but failed to get the second SRAM to be accessed via the CPU chip selects. The TA's provided quite a bit of suggestions and help, but we found out in the end that we were the only group to try multiple chip SRAM access exclusively via the CPU; other groups resorted to using inexpensive logic on the FPGA to achieve the same result. Sometimes, retreat is the best policy; to be more specific, we switched to the logic of the FPGA due to time constraints.
Retreat isn't much of an option when it comes to the DCT implementation, however. Since one of the focuses of our design is speed, a smaller (and therefore faster) multiplier would serve the design parameter nicely. Research into the minimum precision of the 1-D column and row DCT's was then implemented with the sample image files as a baseline. After a few iterations of experiments, it was determined that a 10-bit implementation for the first 1-D column DCT was sufficient as long as a second, larger, 12-bit implementation for the 1-D row DCT followed. This result will help our space constraints tremendously.
Besides the processor and FPGA, the DIO interface provided additional obstacles. Using the LabView VI script provided to us by the TAs was fairly simple, as we only need to create a script generation program that creates a script file from the raw image for downloading onto the SRAM. However, due to considerable amount of time spent downloading the image through LabView, when we found out about the availability of NIDAQ library for C we decided to create direct software interfaces using the library as the downloading time is cut down considerably. The only caveat with using the direct software interface is that for some unknown reasons we would often end up with a few bytes of errors. But since the errors were barely noticeable in the entire image, we couldn??/font>t spend any more time on tracking down the reliability problem, as the errors were random and sporadic.
![]()
As some of the CAD tools used this semester are brand new, inevitably there are some tuning and adjusting of the tools to make them work for us. While some of the delay in the functionality of the CAD tools had caused major havoc on other teams' schedules, we were fortunate that most of the tools were working right around the time when we need them. Accessing the CPU in the early stage with PCBug was quite a learning experience in itself. Although it is a tool used by many to program the CPU, the inadequate manual that was provided to us resulted in considerable time spent by the group trying to figure out how to make PCBug work for us.
HiWare is another CAD tool that worked for us but also worked against us in some ways. HiWare Debugger turned out to be a real nice simulator of the Motorola processor for debugging source codes, and the Burner was very useful for converting the program into the S-file format that we need to download the program onto the processor using PCBug. HiWare Linker was another program that we had to get familiarized with, but fortunately the staff were able to help us with the operation of the Linker. After the HiWare monitor was released in time shortly before demo 1, the group decided to abandon PCBug in favor of HiWare monitor because of other features that the HiWare offers. This decision leads to more time spent trying to get familiarized with the tool. However, since we didn't have a need for the HiWare monitor up to this point, the delay in HiWare monitor didn't really affect us. One way the HiWare monitor had derailed us was that after getting memory banking to work successfully program using PCBug, the memory banking doesn't work anymore when we started using HiWare Monitor. After numerous attempts were made at trying to make memory banking work through CPU, the group finally decided to abandon the idea and instead do it through FPGA. This is just another case of how different CAD tools can affect the progress of the project.
Synplify was pretty familiar to the group, so it didn't create any problems for us. However, the design manager posed minor problems when we had problem performing place and route on one computer. Later, when we switched to a different computer, the problem disappeared, which was quite puzzling. We also found out about the LogiBlox components that can aid in the design process, as they are pre-built logic components that take up considerably less space. Other alternatives will also be explored to decrease the area used on the FPGA.
LabView worked pretty well after the final version of DIO frontend was release, which was very nice. The timing of the release was pretty close to the time when we started using DIO, which worked out nicely for the group. After the frontend was finished, the downloading and uploading of the data to and from SRAM became an easy task. To aid in the downloading of the raw image data, a program was writting to convert the image file into the script that can be downloaded through DIO. Later in the semester, because of the availability of NIDAQ libraries for DIO interface was found, and we moved away from LabView as it is much too slow compared to direct software interfaces using the NIDAQ library.
![]()
Since this is the first time that we as a group attempts to perform codesign, we have encountered various issues concerning codesign. The foremost issue to be considered in codesign is, of course, the hardware/software tradeoffs. Initially, we thought that the FPGA was big enough to fit quite a few logics in it to fit most of the things we wanted. However, later we found out that we have trouble even fitting just the DCT onto the FPGA. This forced us to scale down our design, but the overall hardware/software split did not change much. Another lesson of codesign learned is the ease of implementation. The FPGA can be implemented quite easily with Verilog language and the fully functional Design Manager. CPU, on the other hand, was quite slow and hard to program to accomplish some of the tasks that we had planned. One other point about codesign encountered is the contention of the memory by both FPGA and CPU. We initially try to resolve the memory problem by attempting to perform memory banking using the CPU. However, as indicated in the technical section, we later had to abandon the idea of using CPU to perform the memory banking and resort to using the FPGA, after a great deal of time were spent on trying to get the CPU to work.
One thing that we did not do, in the process of codesign, is to perform co-simulation using Verilog and C. Co-simulation was recommended at the beginning of the project, but the group kind of approached the problem from the bottom up, tackling each part separately and just getting them to work. However, we were not sure if next time we are designing the project again we would perform co-simulation. Due to our experience with other CAD tools this semester, we were not sure how fast we could get the co-simulation tools in Cadence to work for us. If the learning period with the co-simulation program is long, we might not have the time to complete both the co-simulation and the project itself. Also, in our case, since the hardware and software parts communicate asynchronously, co-simulation would not provide too much useful insight. However, if a cycle-accurate co-simulator is available, we might use that to simulate the entire processor to get an idea of how fast or how slow the processor might be.
![]()
There are various project lessons learned up to this point. The most important being the schedule estimates, as we were too optimistic in our scheduling. We failed to take into account time needed for software and hardware troubleshooting. As a lot of software tools and hardware are used for the first time for the course, considerations weren't given to account for the readiness of the CAD tools. Because of the inability to have some of the tools up and running as planned, it has cut into our scheduling somewhat. Luckily, we managed to make up for the lost time with good coordination within the group.
Another lesson learned is planning for allocation of resources. Because we didn't expect as much difficulty as we are encountering right now with the CPU, we didn't allocate enough resources to attack the CPU portion earlier. If given a chance to redo the planning, more resources would have been relegated to the CPU portion as it is taking up considerable amount of manpower just to get minor portion working correctly.
Included in the schedule lesson is, of course, the time budgeting lesson. Up till now, ninety percent of the time was spent on only approximately ten percent of the problems, which is very typical in an engineering design process. A lot of these circumstances could not have been foreseen, therefore we just have to deal with each problem as it arises.
One additional lesson would be the methods of communication. As the project progresses on, communications between team members are essential, as each member is responsible for a different part of the project such that a miscommunication between any two members might result in wrong outputs and time spent debugging will be enormous. As the course progressed along, we realized that short and frequent e-mails between team members on the current status of the project kept things in perspective.
![]()
10. Co-simulator Functionality
As mentioned before in the co-design lesson, one useful functionality for a co-simulator would be its ability to produce cycle-accurate results. With the cycle-accurate results we would then be able to predict the speed of the processor and then maybe make modifications in the early stages to optimize the design. However, this function probably needn??/font>t be implement in the immediate future.
For the immediate future, the minimal functionality needed for Verilog would probably be continuous assign and primitive gates, as these are the fundamental building blocks. But, since Verilog portion will most likely be implemented on FPGA, it would be nice to include some of the modules specific to the FPGA, like some of the RAM modules. The single stepping debug that came with HiWare was very useful, so it would be nice to see single stepping implemented in the co-simulator as well, though that might be somewhat difficult.
![]()
In the end, we were able
to complete the project with plenty of time to debug. Even though we have
encountered minor difficulties with the scheduling and technical problems,
we were able to pull through each time because one of the team members
would be able to make break-through to put us right back on track. The
CAD tools have not been a major problem for us for the most part of the
project, which is nice. Sometimes to make a CAD tool work for us, we have
to twist and turn the program, and create other program to make the tool
even easier to use. Overall, it was a great course, and the importance
of teamwork prevailed.