11K Latin Texts
Here's a bunch of OCR'd Latin texts from the Internet Archive used in our JCDL 2011 and JoCCH 2012 papers (see below). These are all texts that have been identified as being written primarily in Latin (via automatic language ID on the text of the book + manual confirmation). The data released here consists of the entire books, not just the Latin portions (though the Latin parts can easily be extracted by running language ID (e.g., langid.py) on them.What's useful about this data is:
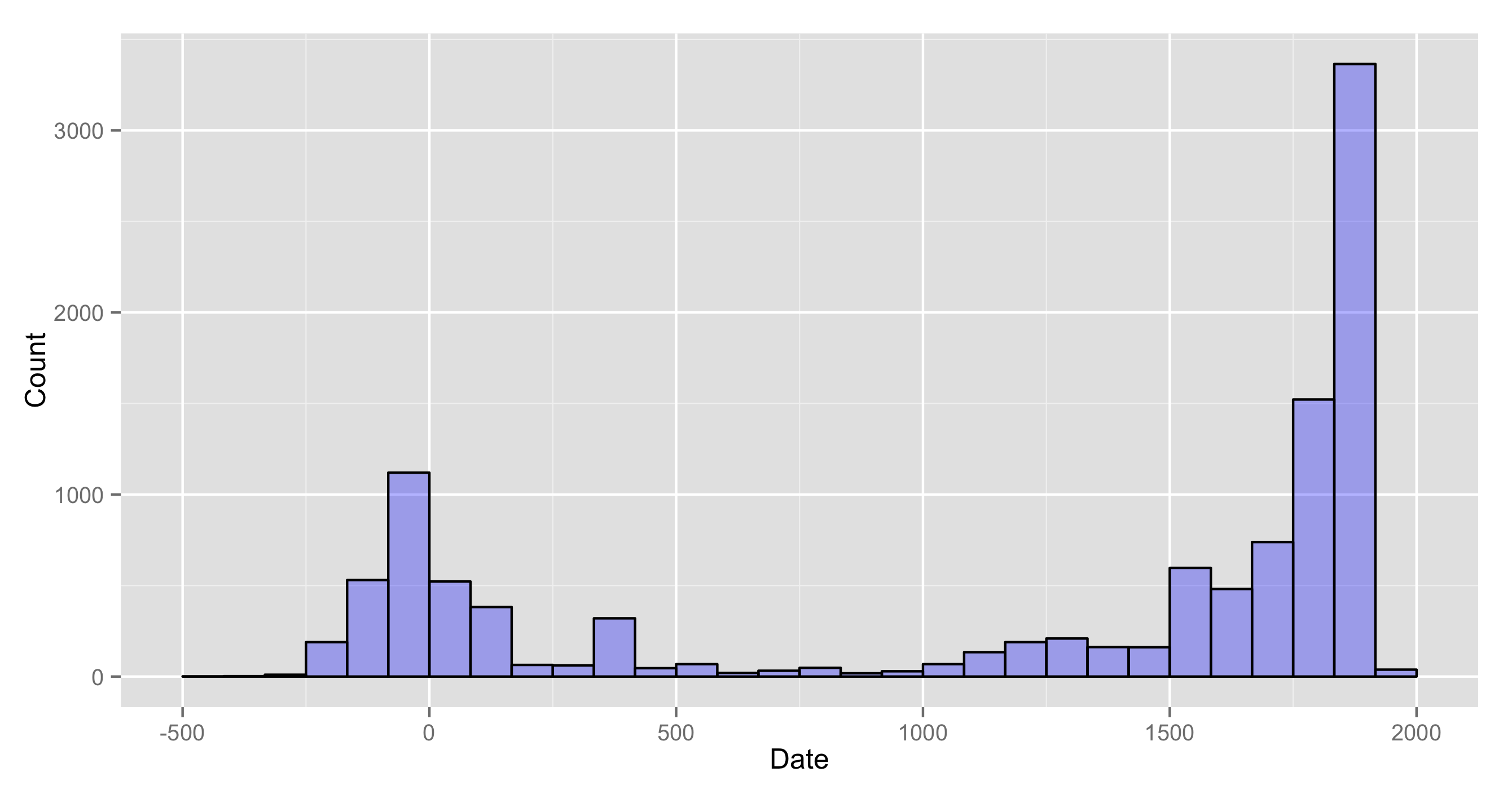
- It's big (11,261 texts spanning two millennia, containing 1.38 billion tokens in total).
- The metadata for these volumes contains not just the date of publication for a specific edition of a work, but a window for the date of composition as well (as determined by undergraduate students in Classics; see JCDL 2011 for more details), which enables historical analysis that the date of publication can't. The metadata may have a few errors and style differences between the different annotators, but I'm putting it up on Github for version control if anyone spots mistakes and wants to correct them.
Data
- All texts in DJVU XML, with formatting for paragraph/line breaks, etc. (9GB) [Download]
- All texts in plain text format (3.9GB) [Download]
- Metadata [Github repo]. For those who'd like to contribute, an additional 10,248 likely Latin texts from the Internet Archive await estimation of their date of composition in that repo (and we can add those texts to the corpus once they've been dated.)
Word Embeddings
As one example of what you can do with this data (noisy as it is), here are 100-dimensional word embeddings for 2,961,867 Latin word types found by running word2vec on the entire corpus. (Use findsimilar.py to find closest terms for any query.) There's a great research project to be had using low-dimensional embeddings like these + the small training data in the Latin treebank and elsewhere to build a great out-of-domain POS tagger/syntactic parser/named entity recognizer.- Latin embeddings (2.6G)
> vinum vinum 1.0 oleum 0.894354480555 yinum 0.858317845967 vinum^ 0.842112594341 vinura 0.83957568134 vinum; 0.822299200682 vinuni 0.821769408403 bibere 0.807991818248 vino 0.800621695189 potum 0.79569430363 > amo amo 1.0 diligo 0.774796101974 doleo 0.747367250735 gaudeo 0.746037276053 amavi 0.712329502828 odi 0.707246956214 laudo 0.70180182963 amas 0.694574626822 facio 0.693545457507 amo; 0.692264420071 > canis canis 1.0 lepus 0.714111694504 felis 0.713660779852 piscis 0.691726821547 serpens 0.679602742502 ovis 0.663469608113 rabidi 0.660877606572 vulpis 0.659607780275 equus 0.656672813035 frigidus 0.656263352602
OCR quality
The OCR quality varies by volume but is generally abysmal (but that may be ok for what you want to use it for.) Here are two samples at the extremes:
lam si qui ex Homero aliisque eum pleraque hausisse dicunt, posteriorum omnino ea condicio est, ut quae nova invenerint, si quando ab antiquiore eadem dicta esse repertum sit, ab eo sua
tkei: SiiimiemfiBgMiffem^ ^mvemsfimUttrUffHk^ &rejcijps inejiyfmteneris in 4rimiiQjuem im ntprtHisjC^JiiSdnmalibHsJk- fim ego exf€r$mJkm)iMdem TaionefimUiter concUdert msfiffuYowza!
Publications
- David Bamman and Gregory Crane (2011) "Measuring Historical Word Sense Variation" (JCDL 2011)
- David Bamman and David Smith (2012), "Extracting Two Thousand Years of Latin from a Million Book Library" (JoCCH 2012)