Before we address the two specific shortcomings for selecting data mentioned above, let us include a description of the unit selection algorithm we have been using, because its method helps offer an answer to those questions.
This general unit selection method is first described in [3] which also includes some techniques of both [6] and [10] in it. The general idea is to take all units of a particular type and define an acoustic distance between them. In the experiments presented here the types are phones, though they could be diphones or demisyllables. Using features such as phonetic, metrical and prosodic context find which features can best split the cluster such that the mean acoustic distance is smaller. Then recursively apply this splitting until some threshold size is achieved. Thus using CART techniques [4] we end up with a decision tree indexed by features available at synthesis time identifying clusters of acoustically similar units.
More formally, we define the acoustic distance ![]() between
two units
between
two units ![]() , and
, and ![]() where
where ![]() as
as
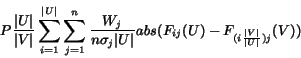
We can then define the impurity of a cluster as
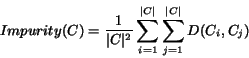
Run-time synthesis consists of selecting the appropriate cluster using the CART trees and then finding an optimal route through these candidate units using a Viterbi decoding algorithm.
Of course there are many degrees of freedom in such a system, including the definition of an acoustic distance - both the parameterization and their relative weights - which must correlate with human perception of speech. We have found that pitch synchronous Mel-frequency cepstral coefficents to be a useful representation, and use mean weighted Mahalanobis distances over the frames in two units with a duration penalty, [3] also included delta cepstral coefficients but at least in our more recent databases we have not found them useful.
An important by-product of this particular unit selection algorithm is a classification of the acoustically distinct units in a database. Each cluster in the tree represents an acoustically distinct typical unit. Thus, given a large database with broad enough coverage, we can automatically find out what acoustically distinct units are and what are contexts they are likely to appear in.
Of course with speech, you can never be completely sure that your distinctions are fixed, but they are reasonable approximations. The distinctions found in this process are database-specific, as well as speaker and style specific, but if the seed databases is of a reasonable coverage, they may be useful in defining selection criteria for a corpus with better coverage.