For English, a lexicon is required to give pronunciations of words, though as all lexicons will be incomplete there is also a requirement for a mechanism for giving pronunciation of words not found in the lexicon. For the example voices in the basic Flite distribution, we based our lexicon on the CMUDICT 0.6 (a slightly later version than distributed with standard US English Festival voices).
After several experiments with lexical tries, and finite state machine mechanisms to represent the entries it was found that simple sorted lists of characters and phones were the most compact form. Phones are encoded with single bytes which the letters are left as simple ASCII. Because our lexicons also distinguish some homographs, there is an extra character users to denote part of speech. Each word in the lexicon is converted to a list of letters (plus part of speech) and held in a sorted table, each entry has an index into a list of phones (with lexical stress marked on vowels). We exclude entries from this list that our letter to sound rules get perfectly correct. The full list consists of 112,340 entries, after pruning we are left with about 50% of these. Note CMUDICT is particular hard due partly due to it containing many proper name. The letters and phones take up 1.559 megabytes.
Our letter-to-sound rules are built using CART techniques as described in [2] and [5]. But in order to make a smaller representation, we further minimize the generated CART trees as follows: each tree is treated as a finite state transducer whose arcs are labeled with the questions on the nodes of the CART tree plus their answers. Thus each state in the FST has two arcs one labelled ``QUESTION_Y'' and the other labelled ``QUESTION_N'', where QUESTION is simply a textual representation of the question in the CART tree. The final states of the FST output the predicted phone. We then use a standard FST minimization algorithm to reduce the FST, thus merging much of the later states in the tree, we call this a decision graph. For example the basic decision tree for the letter V (in one instance) looks like

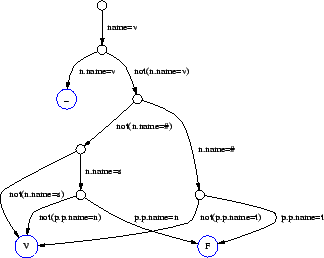
The exception list is still too big for most people's use, and we should prune it further based on word frequency. Typically, very common words and very rare words have non-standard pronunciations, and we could afford to remove some of the very rare words from this lexicon.