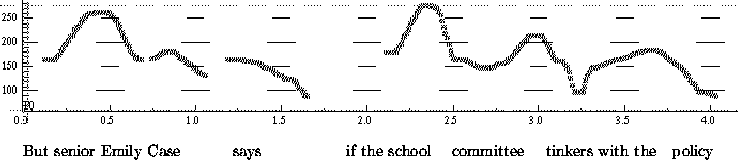Click image to hear synthesised speech using original contour
Click image to hear synthesised speech using generated contour
Thus for our three experiments our results are outlined in Table 4

Table 4: Comparison of overall results
These results compare favourably with a statistically trained F0 generation model for ToBI labelled data [2] (RMSE 34.8Hz and correlation 0.62) and [6] (RMSE 33Hz). Note these experiments were all carried out on the same database though they may have had different training and test sets.
Figure 2 shows an original smooth contour (above) from our test set and the generated contour using our prediction method (below) from the models created in experiment 1. Two points deserve comment. The difference at the phrase break in the middle of the example is due to our predicted contour being interpolated through unvoiced regions next to silence, unlike the original smoothed F0. Hence the breaks appear greater in the above original. The second point concerns the accent around the words ``the policy''. The original accent actually goes over the two words while the predicted one has a more restricted accent on the first syllable of ``policy'', it is possible to hear the difference but it is not significant.