Activity Recognition from First Person Sensing
People
Fernando De la Torre
Martial Hebert
Description
We study the problem of simultaneous segmentation and activity classification from wearable sensors in an uninstrumented environment. Temporal segmentation of human motion into actions is central to the understanding and building of computational models of human motion and activity recognition. Several issues contribute to the challenge of temporal segmentation and classification of human motion. These include the large variability in the temporal scale and periodicity of human actions, the complexity of representing articulated motion, and the exponential nature of all possible movement combinations. This work provides initial results from investigating two distinct problems - classification of the overall task being performed, and the more difficult problem of classifying individual frames over time into specific actions. We explore the use of a first-person camera and Inertial Measurement Units (IMUs) for temporally segmenting human motion into actions and performing activity classification in the context of cooking and performing recipes in a natural environment. We present baseline results for supervised and unsupervised temporal segmentation, and recipe recognition in the CMU-Multimodal activity database (CMU-MMAC).
 |
| Figure 1. Action segmentation and classification from multiple modalities from the CMU-MMAC dataset. |
This dataset differs from other activity recognition databases as it contains a multitude of daily activities from a large number of people. The subjects were asked to perform the recipes in a natural way, and no instructions were given as to how to perform each task. The actions vary greatly in time span, repetitiveness, and manner of execution. In addition to the variety of actions, this dataset contains key modalities that directly relate to the person's perspective - wearable IMUs and first-person vision.
There are several challenges posed by the data set, including annotating the data, variability in action execution, object recognition and scene detection. As an initial step to exploring the dataset, we first consider possible levels of annotating actions. After initial evaluation of the data, we have found that data labeling of everyday activities is ambiguous due to the various ways a task can be performed and described. For instance, we can label at the recipe level (e.g. "beat two eggs in a bowl"), at a more detailed action level (e.g. "break an egg"), or at a very fine-grained level of simple movements (e.g., "reach forward with left hand"). As a first step to evaluating performance of action recognition on this dataset, we label 35 actions for 16 subjects making brownies, as shown in the following table:
|
||||||||||||||||||||||||||||||||||||||||||
| Table 1. The 40 actions chosen to annotate the Brownies recipe data. | ||||||||||||||||||||||||||||||||||||||||||
Another challenge in this dataset is the great variety of performing each of the daily kitchen actions observed, as no instructions of how to perform the recipe were given to the subjects. For example, one of the subjects pours the brownie mix in the bowl of beaten eggs and then stirs the ingredients, while another stirs while pouring in the brownie mix, and yet a third person stirs while holding a second utensil in the mix (see the figure below). This diversity presents ambiguity in describing the action as either "pouring in mix" or "stirring mix," or as a separate action "pouring in mix while stirring."
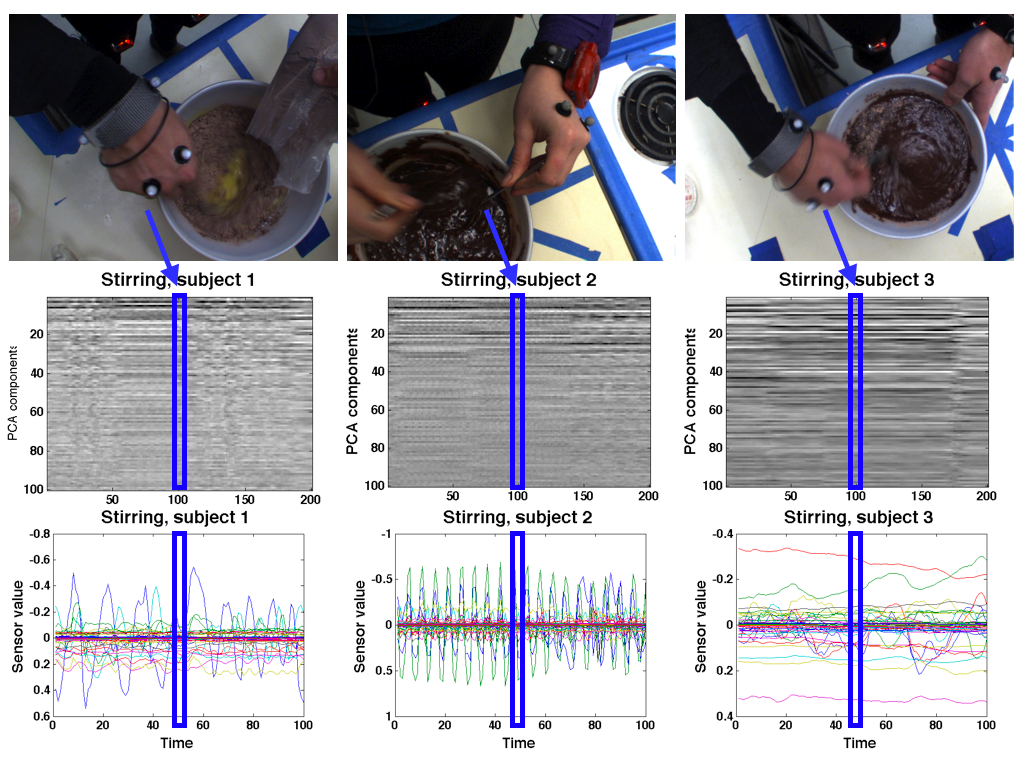 |
| Figure 2. Examples of various ways subjects stirred the brownie mix - first pouring in the brownie mix, then stirring; stirring while pouring in the brownie mix; stirring while holding two utensils. Top row is first-person vision, middle row is the top 90 components of the gist for 100 frames before the snapshot, and 100 frames after the snapshot, bottom row is IMU data for some time interval (approximately 7 seconds total length). |
Baseline results
We used several standard algorithms for per-frame classification of withheld people using cross-validation. The best parameters for supervised HMM and KNN yielded the following results on 16 subjects, 35 actions:| Algorithm | IMU-only | Video-only | Multimodal |
|---|---|---|---|
| HMM | 16% | 9.2% | 21.8% |
| KNN | 30.7% | 32.2% | 36% |
References
Ekaterina H. Spriggs*, Fernando De La Torre, and Martial Hebert, "Temporal segmentation and activity classification from first-person sensing," IEEE Workshop on Egocentric Vision, CVPR 2009, June, 2009.Funding
This research is supported by:
- NSF Grant EEEC-0540865