We now present some experimental results from an implementation of the system. The main data set we use is a collection of 366 technical reports from the Carnegie Mellon University School of Computer Science (our set essentially consists of all reports available online as of August 1995). This set consists of just over 30MB of text. Table 1 gives the distribution of matches when each document is searched against all others.
![]()
: Match Distribution for CMU-SCS Technical Report Data Set.
The number in parenthesis in the right hand column is the number of non-identical document matches (i.e. 372 - 366). Note that there were 763 matches at the 1% level, which is about two 1% matches for each document. This is higher than expected. It reflects the fact that the data set has a high degree of low-level correlation: it is generated by a relatively small group of people with shared experiences and background (for example, people in this group tend to cite each other's work). Some of these low-level commonalities would be removed by the technique described in Section 6.2, however the data set is too small for this technique to remove all of them. The web-based implementation of the system has a larger database (about 3000 documents) that includes the technical report data set. When a technical report is matched against this larger database, we typically find twice as many 1% matches as we obtain when matching against just the technical report database. This means that the 2600 other documents are generating about as many 1% matches as the technical reports (i.e. a 1% match rate that is 7 times lower). This is partly because this data set is larger, but also because it does not have the same degree of low-level correlation (the 2600 ``other'' documents are technical reports and papers from a wide variety of different institutions).
Table 2 compares fixed size selective fingerprinting with full fingerprinting for a small collection of documents, and provides evidence of the reliability of selective fingerprinting. The left hand column gives the match ratios reported by our system, and the right hand column gives the results for full fingerprinting as both a match ratio and as raw data (common-substrings/total-substrings). For this small collection of documents, selective fingerprinting gives match ratios that are within a factor of two of full fingerprinting, and usually much closer.
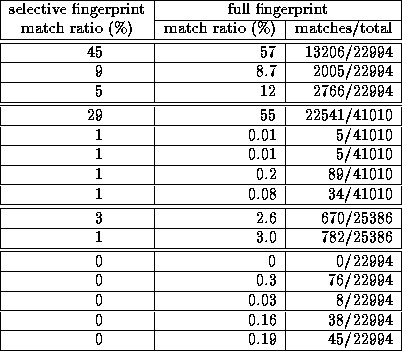
: Comparison of Selective Fingerprinting and Full Fingerprinting.
To establish the utility of the techniques for reducing false positives, we present two collections of data. Table 3 considers both (a) dropping frequent substrings during searching and (b) cutting the first 1000 characters of a document. The first line of the table gives the match ratio distribution for matching all documents against all documents with both techniques (a) and (b) enabled. The second line disables just (a), and the third line disables just (b). The final line disables (a) and (b). Both techniques are very useful in isolation, but it is clear that they address overlapping issues. They are, however, sufficiently different to be useful in tandem.

: Reducing False Positives I: frequency checks (search) & document preamble.
Table 4 considers the effectiveness of focusing on infrequent substrings during fingerprint generation (Subsection 6.1). The first line give the baseline match ration distribution, and the second line gives the same results when substrings are selected without regard for frequency. This table indicates a reduction of false positives by more than a factor of two.
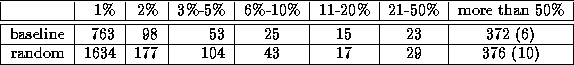
: Reducing False Positives II: use of infrequent substrings in fingerprints.
The next two tables investigate the effect of fingerprint size. In Table 5, the size of the stored fingerprint is varied from 10 to 500 (the baseline value is 100), while the search fingerprint remains constant at 1000. In Table 6, the size of the search fingerprint is varied from 100 to 5000 (the baseline value is 1000), while the search fingerprint remains constant at 100. The results indicate that our system is surprisingly insensitive to changes in fingerprint sizes. The use of 100 for storage and 1000 for searching yields a good tradeoff between search reliability and the level of positive matches.

: Effects of Varying Stored Fingerprint Size.
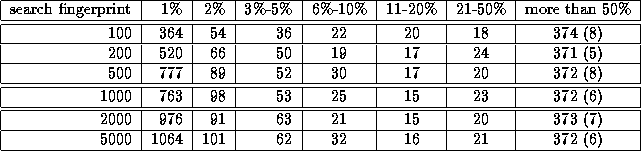
: Effects of Varying Search Fingerprint Size.
Finally, table 7 shows the effect of changing ![]() , the length of character
subsequences, from 10 to 50 (the baseline value is 20). As expected, decreasing
, the length of character
subsequences, from 10 to 50 (the baseline value is 20). As expected, decreasing
![]() has the effect of significantly increasing the number of low level matches.
Increasing
has the effect of significantly increasing the number of low level matches.
Increasing ![]() has the effect of decreasing both the number of low-level and
high-level matches.
has the effect of decreasing both the number of low-level and
high-level matches.
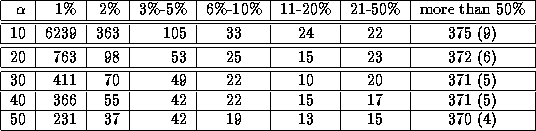
: Effects of Varying Substring Length.