
|
Temporal Shape-From-SilhouetteGerman Cheung, Simon Baker, Takeo KanadePlease contact German Cheung at german@ux2.sp.cs.cmu.edu for further details |
|
|
Temporal Shape-From-SilhouetteGerman Cheung, Simon Baker, Takeo KanadePlease contact German Cheung at german@ux2.sp.cs.cmu.edu for further details |
| Return to Homepage | RealTime 3D Reconstruction | Temporal SFS | Human Kinematic Modeling and Motion Capture | Human Motion Transfer |
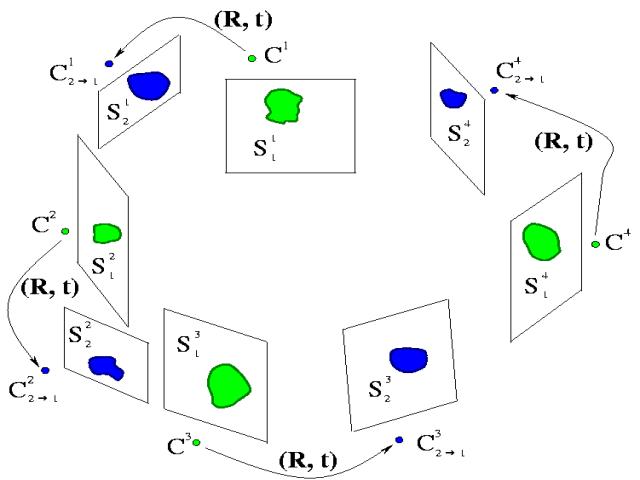
| Step 1: Constructing Bounding Edges |
Step 2: Extracting Colored Surface Points (CSPs) |
Step 3: Aligning Visual Hulls through CSPs | Step 4: Visual Hull Refinement |

|

|

|
|
| One of the input images | Bounding edges | Unaligned CSPs | Aligned CSPs | Visual Hull built using 6 images | Visual Hull built using 126 images |

|

|

|

|

|

|
| One of the input images | Bounding Edges | Unaligned CSPs | Aligned CSPs | Visual Hull built using 6 images | Visual Hull built using 90 images |

|

|

|

|

|

|
| One of the input images | Bounding Edges | Unaligned CSPs | Aligned CSPs | Visual Hull built using 6 images | Visual Hull built using 90 images |

|
|

|

|

|

|
| One of the input images | Unaligned CSPs | Aligned CSPs |
Aligned and Segmented CSPs with estimated joint location |

|

|

|

|
| One of the input images | Unaligned CSPs | Aligned CSPs | Segmented CSPs | Visual Hull built using 16 images | Visual Hull built using 104 images |

|

|

|

|

|

|
| One of the input images | Unaligned CSPs | Aligned CSPs |
Aligned and Segmented CSPs with estimated joint location |

|

|

|

|
| One of the input images | Unaligned CSPs | Aligned CSPs |
Aligned and Segmented CSPs with estimated joint location |

|

|

|

|