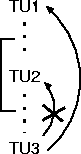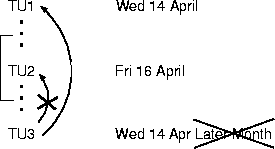The main purpose of a focus model is to make an appropriate set of discourse entities available as candidate antecedents at each point in the discourse. As described above in Section 4.3, Grosz and Sidner's model captures situations in which entities should not be available as candidate antecedents, and Rosé et al. identify situations in which Grosz and Sidner's model may incorrectly eliminate entities from consideration (i.e., dialogs with multiple threads). The potential challenge for a recency-based model like ours is that entities may be available as candidate antecedents that should not be. An entity E may occur to which an anaphoric relation could be established, but an entity mentioned before E is needed for the correct interpretation. (From another perspective, E yields the wrong interpretation but cannot be ruled out as a possible antecedent.) To assess the magnitude of this problem for our method, in this section we characterize the cases in which the most recent entity is not an appropriate antecedent.
Before proceeding, we note that there is only one situation in which our model incorrectly makes a needed entity unavailable. Recall from Section 4.3 that, for a particular relation R, only the most recent Temporal Unit for which R can be established is a candidate (call it C). The problem arises when the correct interpretation requires that that same relation R be established with an entity mentioned earlier than C. This is a problem because the earlier time is not a candidate. If such cases were to occur in the training data, they would have been found by the analysis presented below. However, none were found.
Based on the anaphoric chain annotations, we identified how far back on the focus list one must go to find an antecedent that is appropriate according to the model. An antecedent is considered to be appropriate according to the model if there exists a relation defined in the model such that, when established between the current utterance and the antecedent, it yields the correct interpretation. Note that we allow antecedents for which the anaphoric relation would be a trivial extension of one of the relations explicitly defined in the model. For example, phrases such as ``after lunch'' should be treated as if they are simple times of day under the co-reference and modify anaphoric relations, but, as explicitly defined, those relations do not cover such phrases. For example, given Wednesday 14 April, the reference ``after lunch'' should be interpreted as after lunch, Wednesday 14 April under the co-reference relation. Similarly, given 10am, Wednesday, 14 April, ``After lunch'' in ``After lunch would be better'' should be interpreted as after lunch, Wednesday 14 April under the modify anaphoric relation.
The results are striking. Between the two sets of training data, there are only nine anaphoric temporal references for which the immediately preceding Temporal Unit is not an appropriate antecedent, 3/167 = 1.8% in the CMU data, and 6/71 = 8.4% in the NMSU data.
Figure 9 depicts the structure involved in all nine cases. TU3 represents the anaphoric reference for which the immediately preceding Temporal Unit is not an appropriate antecedent. TU1 represents the most recent appropriate antecedent, and TU2 represents the intervening Temporal Unit or Units. The ellipses represent any intervening non-temporal utterances.
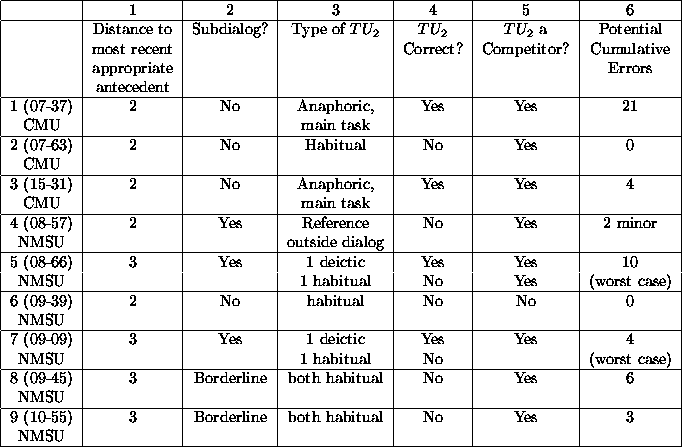
Figure 10 characterizes the nine cases along a number
of dimensions.
To isolate the issues addressed, it was assumed in deriving these figures that the
dialog is correctly interpreted up to and including TU1.
In three of the cases (rows 2, 4, and 9, labeled 07-63, 08-57, 10-55, respectively), there is a correct deictic interpretation of TU3under our model, in addition to the correct (with antecedent TU1) and incorrect (with antecedent TU2) anaphoric interpretations.
Column 1 of Figure 10 shows that, in all three cases in the CMU data and in two cases in the NMSU data, the second most recently mentioned Temporal Unit is an appropriate antecedent. In the remaining four cases, the third most recently mentioned time is appropriate.
In three of the cases, the references represented by TU2 in Figure 9 are in subdialogs off the main topic and scheduling task (indicated as ``Yes'' in column 2). All of these subdialogs are in the NMSU data. In four cases, the TU2references are in subsegments that are directly in service of the main task (indicated as ``No'' in column 2), and in two cases, we judged them to be borderline.
Column 3 characterizes the type of reference the TU2 references are.
The two marked ``Anaphoric, main task'' are specific references to times that
involve the main scheduling task. The
subdialog marked ``Reference
outside dialog'' (row 4, label 8-57)
is shown in Figure 11.
The main topic of this dialog is a party for the anniversary mentioned in TU1. The TU2 reference, ``around six in the morning,'' involves the participants' shared knowledge of an event that is not related to the scheduling task. The only interpretation possible in our model is six in the morning on the day specified in the TU1 reference, while in fact the participants are referring to six in the morning on the dialog date. (There is currently no coverage in our model for deictic references that mention only a time of day.) Thus, the interpretation of the TU2 reference is incorrect, as indicated in column 4.
Many of the TU2 references are habitual (marked ``habitual'' in column 3 of Figure 10). For example, the participants discuss their usual work schedules, using utterances such as ``during the week I work from 3 to 6.'' Since there is no coverage of habituals in our model, the interpretations of all of the TU2 habitual references are incorrect, as indicated in column 4.
We now turn to column 5, which asks a key question: is TU2a competitor? TU2 is a competitor if there is some relation in the model that can be established between TU3 and TU2. In the cases in which TU2 represents multiple utterances (namely, the fifth, seventh, eighth, and ninth rows of Figure 10), ``yes'' is indicated in column 5 if an interpretation of the segment involving both of the TU2 references is possible. Cumulative error (column 6) can be non-zero only if the entry in column 5 is ``Yes'': if the TU2 references are not competitors, they cannot be antecedents under our model, so they cannot prevent TU3 from being recognized as a correct antecedent.
It is important to note that the incorrect interpretation of TU3 and the cumulative errors indicated in column 6 are only potential errors. In all cases in Figure 10, the correct interpretation of TU3 involving TU1 is available as a possible interpretation. What is shown in column 6 is the number of cumulative errors that would result if an interpretation involving TU2 were chosen over a correct interpretation involving TU1. In many cases, the system's answer is correct because the (correct) TU3-TU1 interpretation involves the co-reference anaphoric relation, while the (incorrect) TU3-TU2interpretation involves the frame of reference anaphoric relation; the certainty factor of the former is sufficiently larger than that of the latter to overcome the distance-factor penalty. In addition, such interpretations often involve large jumps forward in time, which are penalized by the critics.
The worst case of cumulative error, row 1, is an example.
The segment is depicted
in Figure 12.
It should be noted that,
if times rather than days or months were being discussed,
the correct interpretation for TU3 could be obtained
from TU2 under the modify anaphoric relation.
A good example of this occurs in the corpus example in Figure
1, repeated here as Figure 14.
Returning to column 6 of Figure 10, note that two of the cumulative error figures are listed as ``worst case.'' These are cases in which there are two TU2 references and there are many different possible interpretations of the passage.
Notice that the second and fourth rows correspond to cases in which TU2 is a competitor, yet no significant potential cumulative error results (the minor errors listed for row 4 are due to the relation not fitting exactly, rather than an error from choosing the wrong antecedent: six in the morning rather than in the morning is placed into the high specificity fields). In both of these cases, the error corrects itself: TU1 is incorrectly taken to be the antecedent of TU2, which is in turn incorrectly taken to be the antecedent of TU3. But TU2 in effect copies over the information from TU1 that is needed to interpret TU3. As a result, the interpretation of TU3 is correct.
In the cases for which there are only a few potential cumulative errors, either a new, unambiguous time is soon introduced, or a time being discussed before the offending TU2 reference is soon reintroduced, getting things back on track.
An important discourse feature of the dialogs is the degree of redundancy of the times mentioned [39]. This limits the ambiguity of the times specified, and it also leads to a higher level of robustness, since additional Temporal Units with the same time are placed on the focus list and previously mentioned times are reintroduced. Table 6 presents measures of redundancy. The redundancy is broken down into the case where redundant plus additional information is provided (Redundant) versus the case where the temporal information is just repeated (Reiteration). This shows that roughly 27% of the CMU utterances with temporal information contain redundant temporal references, while 20% of the NMSU ones do.
|
In considering how the model could be improved, in addition to adding a new modify anaphoric relation for cases such as those in Figures 12 and 13, habituals are clearly an area for investigation. Many of the offending references are habitual, and all but one of the subdialogs and borderline subdialogs involve habituals. In a departure from the algorithm, the system uses a simple heuristic for ignoring subdialogs: a time is ignored if the utterance evoking it is in the simple past or past perfect. This prevents some of the potential errors and suggests that changes in tense, aspect, and modality are promising clues to explore for recognizing subsegments in this kind of data (see, for example, [10,26]).