In this section, we present an example of the how search cost varies with
the tightness of constraints for a class of problems, and describe how this
behavior can be understood in terms of changes in the structure of the
problems, independent of particular search algorithms. This review and
summary of previous studies of the transition then forms a basis for
comparison with the new results presented in subsequent sections.

Figure 1: Typical transition pattern. Median solution cost for
dynamic backtracking (solid line) and probability of a solution
(dashed line) as a function of number of nogoods. Each point
represents 1000 problems of 10 variables and domain size 3, each
solved 100 times. Error bars showing 95% confidence intervals
are included, but are in some cases smaller than the size of the
plotted points.
Figure 1 shows a typical example of the
easy-hard-easy pattern as a function of the
constrainedness of the problem. Problems with few or many constraints
tend to be easy to solve while those with an intermediate number are
more difficult.
The fraction of solvable problems is also shown in
Figure 1, scaled from 1.0 on the left to 0.0
on the right. This illustrates that the hard problems are concentrated in
the so-called ``mushy region'' [19] where the probability
of a solution is changing from 1.0 to 0.0. In particular, the peak in search
cost is near the ``crossover point,'' the point at which half the problems are
solvable and half unsolvable. For this problem class, the crossover
point occurs at just over 75 binary nogoods, and the peak in dynamic
backtracking solution cost occurs at about 85 binary nogoods.
In all of our results in this paper, we include 95% confidence
intervals [20]. These intervals for the
estimate of the median obtained from our samples are given approximately by the percentiles
 of the data, where N is the number of samples.
For the estimate of fractions the intervals are given
approximately by
of the data, where N is the number of samples.
For the estimate of fractions the intervals are given
approximately by 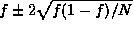 , where f is the estimated value of the fraction.
Finally, for the estimate of means the intervals are approximately
, where f is the estimated value of the fraction.
Finally, for the estimate of means the intervals are approximately
 where
where 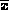 is the estimate
of the mean and
is the estimate
of the mean and  the standard deviation of the sample.
In many cases in this paper,
there are sufficient samples to make these intervals smaller than the
size of the plotted points.
the standard deviation of the sample.
In many cases in this paper,
there are sufficient samples to make these intervals smaller than the
size of the plotted points.
A key point from examples such as this is that the difficult instances within
a class of search problems tend to be concentrated near a particular value of
the constraint tightness (here measured by the number of binary nogoods).
Because this behavior is seen for a variety of search methods, it indicates
this concentration does not depend much on the details of the search
algorithm. Instead, it appears to be associated with a change in the
properties of the problems themselves, namely their solvability.
These observations raise a number of questions, such as why a peak in
search cost exists, why the peak occurs near the transition from
mostly solvable to mostly unsolvable problems and is thus independent
of the particular search algorithm, and why this behavior is seen for
a large variety of constraint satisfaction problems.
The existing explanation for the concentration of hard problems
relies on a competition between changes in the
number of solutions and the amount of pruning provided by the problem
constraints [21]. With few constraints, there are
many solutions so the search is usually easy. As constraints are added
the number of solutions drops rapidly, making problems harder. But
the new constraints also increase the pruning of unproductive search
choices, tending to make search easier. When there are few
constraints, the decrease in the number of solutions overwhelms the
increase in pruning, giving harder problems on average. Eventually
the last solution is eliminated and all that remains is the increased
pruning from additional constraints, leading to easier problems.
Thus the phase transition, the point at which there
is a precipitous change from solvability to unsolvability, more or
less coincides with the peak in solution cost.
All these effects become more pronounced as larger problems are
considered, leading to sharper peaks and more abrupt transitions.
This qualitative description explains many features of the observed
behavior.
This pruning explanation was also offered by [4]
with respect to finding Hamiltonian circuits in
highly constrained problems.
This explanation can also be used to obtain a quantitative
understanding of the behavior. For instance, the location of the
transition region can be understood by an approximate theory
predicting that the cost peak occurs when the expected number of
solutions equals one [19, 21]. In our example there
are  possible assignments to the 10 variables in the
problem. There are
possible assignments to the 10 variables in the
problem. There are
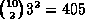 possible binary nogoods
for the problem, which counts the number of ways to select a pair of
variables and the different assignments for that pair. A given
complete assignment for the 10 variables will be a solution provided
each of the selected binary nogoods does not use the same assignment
for its pair of variables as in the given complete assignment. This
leaves
possible binary nogoods
for the problem, which counts the number of ways to select a pair of
variables and the different assignments for that pair. A given
complete assignment for the 10 variables will be a solution provided
each of the selected binary nogoods does not use the same assignment
for its pair of variables as in the given complete assignment. This
leaves
 possible choices for
the binary nogoods. Thus the expected number of solutions is given by
possible choices for
the binary nogoods. Thus the expected number of solutions is given by

for problems with m randomly selected binary
nogoods. This expression equals one at m=82.9, the location of the
observed cost peak. Furthermore, because the expected number of
solutions grows exponentially with the number of variables when m is
smaller than this threshold value and decreases exponentially to zero
when m is larger, the range of m values over which the expected
number of solutions is near one rapidly decreases as variables are
added. This accounts for the observed sharpening of the transition for
larger problems.
A further quantitative success of relating the search cost peak to
transition phenomena is the evaluation of scaling behavior of the
transition and search cost peak [15, 6].
Previous: 2. Some Classes of
Search Problems
Next: 4. Search Difficulty
and Solvability
Return to Contents
Send comments to mammen@cs.umass.edu
Fri Aug 29 12:21:02 EDT 1997