This section starts our treatment of Q-DAGs with a concrete example. We will consider a particular belief network, define a set of queries of interest, and then show a Q-DAG that can be used to answer such queries. We will not discuss how the Q-DAG is generated; only how it can be used. This will allow a concrete introduction to Q-DAGs and will help us ground some of the formal definitions to follow.
The belief network we will consider is the one in Figure 4(a).
The class of queries we are interested in is ![]() , that is,
the probability that variable
, that is,
the probability that variable ![]() takes some value given some known
(or unknown) value of
takes some value given some known
(or unknown) value of ![]() . Figure 4(b) depicts a Q-DAG for
answering such queries, which is essentially a parameterized arithmetic
expression where the values of parameters depend on the evidence obtained.
This Q-DAG will actually answer queries of the form
. Figure 4(b) depicts a Q-DAG for
answering such queries, which is essentially a parameterized arithmetic
expression where the values of parameters depend on the evidence obtained.
This Q-DAG will actually answer queries of the form
![]() , but we can use normalization to compute
, but we can use normalization to compute
![]() .
.
First, a number of observations about the Q-DAG in Figure 4(b):
According to the semantics of Q-DAGs, the value of node ![]() is 1 if
variable
is 1 if
variable ![]() is observed to be
is observed to be ![]() or is unknown, and 0 otherwise.
Once the values of ESNs are determined, we evaluate the remaining nodes
of a Q-DAG using numeric multiplication and addition. The numbers that
get assigned to query nodes as a result of this evaluation are the answers
to queries represented by these nodes.
or is unknown, and 0 otherwise.
Once the values of ESNs are determined, we evaluate the remaining nodes
of a Q-DAG using numeric multiplication and addition. The numbers that
get assigned to query nodes as a result of this evaluation are the answers
to queries represented by these nodes.
For example, suppose that the evidence we have is ![]() . Then ESN
. Then ESN
![]() is evaluated to 1 and ESN
is evaluated to 1 and ESN ![]() is evaluated to 0.
The Q-DAG in Figure 4(b) is then evaluated as given in
Figure [*](a), thus leading to
is evaluated to 0.
The Q-DAG in Figure 4(b) is then evaluated as given in
Figure [*](a), thus leading to
![]()
and
![]()
from which we conclude that ![]() . We can then compute the
conditional probabilities
. We can then compute the
conditional probabilities
![]() and
and
![]() using:
using:
![]()
![]()
If the evidence we have is ![]() , however,
then
, however,
then ![]() evaluates to 0 and
evaluates to 0 and
![]() evaluates to 1. The Q-DAG in Figure 4(b) will then be
evaluated as given in Figure [*](b), thus leading to
evaluates to 1. The Q-DAG in Figure 4(b) will then be
evaluated as given in Figure [*](b), thus leading to
![]()
and
![]()
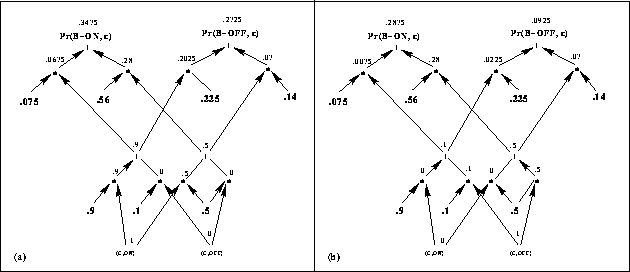
Figure: Evaluating the Q-DAG in Figure 4 with
respect to two pieces of evidence: (a) ![]() and
(b)
and
(b) ![]() .
.
We will use the following notation for denoting variables and their values.
Variables are denoted using uppercase letters, such as ![]() , and variable
values are denoted by lowercase letters, such as
, and variable
values are denoted by lowercase letters, such as ![]() . Sets of variables
are denoted by boldface uppercase letters, such as
. Sets of variables
are denoted by boldface uppercase letters, such as ![]() , and their
instantiations are denoted by boldface lowercase letters, such as
, and their
instantiations are denoted by boldface lowercase letters, such as
![]() .
We use
.
We use ![]() to denote the set of variables about which we have evidence.
Therefore, we use
to denote the set of variables about which we have evidence.
Therefore, we use ![]() to denote an instantiation of these variables that
represents evidence. Finally, the family
of a variable is the set containing
the variable and its parents in a directed acyclic graph.
to denote an instantiation of these variables that
represents evidence. Finally, the family
of a variable is the set containing
the variable and its parents in a directed acyclic graph.
Following is the formal definition of a Q-DAG.

Evidence variables ![]() correspond to network variables about which we
expect to collect evidence on-line.
For example, in Figure [*], C is the evidence variable.
Each one of these variables has a set of
possible values that are captured by the function
correspond to network variables about which we
expect to collect evidence on-line.
For example, in Figure [*], C is the evidence variable.
Each one of these variables has a set of
possible values that are captured by the function ![]() .
For example, in Figure [*], the evidence variable C has values
.
For example, in Figure [*], the evidence variable C has values
![]() and
and ![]() .
The special value
.
The special value
![]() is used when the value of a variable is not known. For example, we may
have a sensor variable with values ``low,'' ``medium,'' and ``high,'' but then
lose the sensor value during on-line reasoning. In this case, we set the sensor
value to
is used when the value of a variable is not known. For example, we may
have a sensor variable with values ``low,'' ``medium,'' and ``high,'' but then
lose the sensor value during on-line reasoning. In this case, we set the sensor
value to ![]() .[+]
Query nodes are those representing answers to user queries.
For example, in Figure [*], B is the query variable, and
leads to query nodes
.[+]
Query nodes are those representing answers to user queries.
For example, in Figure [*], B is the query variable, and
leads to query nodes ![]() and
and ![]() .
.
An important notion is that of evidence:
![]()
When a variable ![]() is mapped into
is mapped into ![]() , then evidence tells
us that
, then evidence tells
us that ![]() is instantiated to value
is instantiated to value ![]() . When
. When ![]() is mapped into
is mapped into
![]() , then evidence does not tell us anything about the value of
, then evidence does not tell us anything about the value of ![]() .
.
We can now state formally how to evaluate a Q-DAG given some evidence. But first we need some more notation:
The following definition tells us how to evaluate a Q-DAG by evaluating each of its nodes. It is a recursive definition according to which the value assigned to a node is a function of the values assigned to its parents. The first two cases are boundary conditions, assigning values to root nodes. The last two cases are the recursive ones.
One is typically not interested in the values of all nodes in a Q-DAG since most of these nodes represent intermediate results that are of no interest to the user. It is the query nodes of a Q-DAG that represent answers to user queries and it is the values of these nodes that one seeks when constructing a Q-DAG. The values of these queries are captured by the notion of a Q-DAG output.
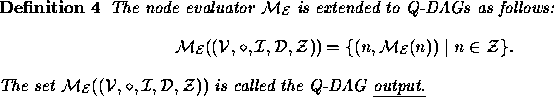
This output is what one seeks from a Q-DAG. Each element in this output
represents a probabilistic query and its answer.
Let us consider a few evaluations of the Q-DAG shown in Figure 4,
which are shown in Figure [*]. Given evidence ![]() ,
and assuming that
,
and assuming that ![]() and
and ![]() stand for the
Q-DAG nodes labeled
stand for the
Q-DAG nodes labeled ![]() and
and ![]() ,
respectively, we have
,
respectively, we have

meaning that ![]() and
and ![]() .
If instead the evidence were
.
If instead the evidence were ![]() , a set of
analogous computations can be done.
, a set of
analogous computations can be done.
It is also possible that evidence tells us nothing about the value of variable
![]() , that is,
, that is, ![]() . In this case, we would have
. In this case, we would have
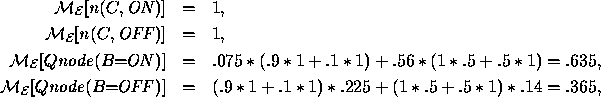
meaning that ![]() and
and ![]() .
.
