Given the basic policy for cooking a single egg with a single pan and whisk, we can construct a policy to achieve the goal by composing the basic policy with a binding. This policy will solve the goal from any state in which the bound material is in a non-postgoal state. For a policy to solve the goal from any solvable state, it must be able to change bindings at run time. We will call a function from states to bindings a binding map.
One simple policy for choosing bindings is to impose some
a priori ordering on the objects and always use the first
acceptable object in the ordering. The ordering might be random,
or it might correspond to order imposed by a visual search mechanism.
From a formal standpoint, the ordering does not matter, so we can,
without loss of generality, use the left-to-right order of state
components in the environment's state tuple.
Let ![]() be some binding map that always chooses the leftmost pregoal material
and uses some fixed mapping for the tools (we do not care what). This
mapping allows us to construct a true solution, and one that requires
no internal state in the agent:
be some binding map that always chooses the leftmost pregoal material
and uses some fixed mapping for the tools (we do not care what). This
mapping allows us to construct a true solution, and one that requires
no internal state in the agent:
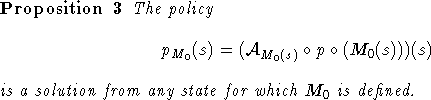
Proof:
By assumption, ![]() is defined in the initial state. The environment
must then map to a solvable state under
is defined in the initial state. The environment
must then map to a solvable state under ![]() in the initial state.
Since p is, by assumption, a solution for the problem in E,
in the initial state.
Since p is, by assumption, a solution for the problem in E,
![]() must solve the problem in E' unless
must solve the problem in E' unless ![]() changes value
before the
changes value
before the ![]() can solve the problem. Suppose it does. Then
the environment must go from a state
can solve the problem. Suppose it does. Then
the environment must go from a state ![]() , in which some state
component of E' is the leftmost pregoal material, to a state
, in which some state
component of E' is the leftmost pregoal material, to a state ![]() ,
in which some other component is the leftmost pregoal material. This
can only happen if (a) the leftmost pregoal material in
,
in which some other component is the leftmost pregoal material. This
can only happen if (a) the leftmost pregoal material in ![]() is
changed to be in a goal state in
is
changed to be in a goal state in ![]() or (b) some other component
that was not pregoal in
or (b) some other component
that was not pregoal in ![]() becomes pregoal in
becomes pregoal in ![]() . Case (b) is
impossible and case (a) implies that
. Case (b) is
impossible and case (a) implies that ![]() is itself a goal state.
Thus
is itself a goal state.
Thus ![]() must be a solution.
must be a solution. ![]()