The most naive strategy for dealing with partial observability is to ignore it. That is, to treat the observations as if they were the states of the environment and try to learn to behave. Figure 9 shows a simple environment in which the agent is attempting to get to the printer from an office. If it moves from the office, there is a good chance that the agent will end up in one of two places that look like ``hall'', but that require different actions for getting to the printer. If we consider these states to be the same, then the agent cannot possibly behave optimally. But how well can it do?
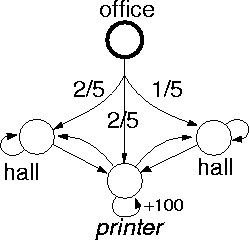
Figure 9: An example of a partially observable environment.
The resulting problem is not Markovian, and Q-learning cannot be guaranteed to converge. Small breaches of the Markov requirement are well handled by Q-learning, but it is possible to construct simple environments that cause Q-learning to oscillate [23]. It is possible to use a model-based approach, however; act according to some policy and gather statistics about the transitions between observations, then solve for the optimal policy based on those observations. Unfortunately, when the environment is not Markovian, the transition probabilities depend on the policy being executed, so this new policy will induce a new set of transition probabilities. This approach may yield plausible results in some cases, but again, there are no guarantees.
It is reasonable, though, to ask what the optimal policy (mapping from observations to actions, in this case) is. It is NP-hard [64] to find this mapping, and even the best mapping can have very poor performance. In the case of our agent trying to get to the printer, for instance, any deterministic state-free policy takes an infinite number of steps to reach the goal on average.