

Next: ARC
Up: Immediate Reward
Previous: Immediate Reward
The complementary reinforcement backpropagation
algorithm [1] (CRBP) consists of a feed-forward
network mapping an encoding of the state to an encoding of the action.
The action is determined probabilistically from the activation of the
output units: if output unit i has activation  , then bit i of
the action vector has value 1 with probability , and 0 otherwise.
Any neural-network supervised training procedure can be used to adapt
the network as follows. If the result of generating action a is
r=1, then the network is trained with input-output pair
, then bit i of
the action vector has value 1 with probability , and 0 otherwise.
Any neural-network supervised training procedure can be used to adapt
the network as follows. If the result of generating action a is
r=1, then the network is trained with input-output pair 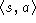 . If the result is r=0, then the network is trained with
input-output pair
. If the result is r=0, then the network is trained with
input-output pair 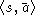 , where
, where 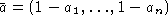 .
.
The idea behind this training rule is that whenever an action fails to
generate reward, CRBP will try to generate an action that is
different from the current choice. Although it seems like the
algorithm might oscillate between an action and its complement, that
does not happen. One step of training a network will only change the
action slightly and since the output probabilities will tend to move
toward 0.5, this makes action selection more random and increases
search. The hope is that the random distribution will generate an
action that works better, and then that action will be reinforced.
Leslie Pack Kaelbling
Wed May 1 13:19:13 EDT 1996