


We assume that an observation is a vector of nominal
values, 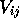 along distinct variables,
along distinct variables, 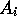 .
A measure of
category utility [Gluck & Corter,
1985; Corter & Gluck, 1992],
.
A measure of
category utility [Gluck & Corter,
1985; Corter & Gluck, 1992],
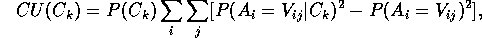
and/or variants
have been used extensively by a system known as COBWEB
[Fisher, 1987a]
and many related systems [Gennari,
Langley & Fisher, 1989; McKusick &
Thompson, 1990; Iba & Gennari,
1991; McKusick &
Langley, 1991; Reich & Fenves,
1991; Biswas, Weinberg & Li,
1994; De Alte Da Veiga, 1994;
Kilander, 1994; Ketterlin, Gancarski & Korczak,
1995].
This measure rewards clusters, 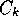 , that increase the
predictability of variable values within
, that increase the
predictability of variable values within  (i.e.,
(i.e., 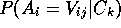 )
relative to
their predictability in the population as a whole (i.e.,
)
relative to
their predictability in the population as a whole (i.e., 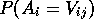 ).
By favoring clusters that increase predictability (i.e.,
).
By favoring clusters that increase predictability (i.e.,
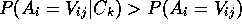 ), we also necessarily
favor clusters that increase variable value predictiveness
(i.e.,
), we also necessarily
favor clusters that increase variable value predictiveness
(i.e., 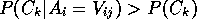 ).
).
Clusters for which many variable values are predictable are cohesive. Increases in predictability stem from the shared variable values of observations within a cluster. A cluster is well-separated or decoupled from other clusters if many variable values are predictive of the cluster. High predictiveness stems from the differences in the variable values shared by members of one cluster from those shared by observations of another cluster. A general principle of clustering is to increase the similarity of observations within clusters (i.e., cohesion) and to decrease the similarity of observations across clusters (i.e., coupling).
Category utility is similar in form to the Gini Index, which has
been used in supervised systems that construct decision trees
[Mingers, 1989b; Weiss &
Kulikowski, 1991].
The Gini Index is typically intended to address the issue
of how well the values of a variable,  , predict a priori
known class labels in a supervised context. The summation over
Gini Indices reflected in CU addresses the extent that a
cluster predicts the values of all the variables.
CU rewards clusters,
, predict a priori
known class labels in a supervised context. The summation over
Gini Indices reflected in CU addresses the extent that a
cluster predicts the values of all the variables.
CU rewards clusters, 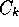 , that most reduce
a collective impurity over all variables.
, that most reduce
a collective impurity over all variables.
In Fisher's [1987a] COBWEB system,
CU is used to measure the quality
of a partition of data, 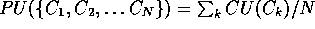 or the average category utility of clusters in the partition.
Sections 3.5 and 5.2 note some
nonoptimalities with this measure of partition quality,
and suggest some alternatives. Nonetheless, this measure is
commonly used, we will take this opportunity to note
its problems, and none of the techniques that we describe
is tied to this measure.
or the average category utility of clusters in the partition.
Sections 3.5 and 5.2 note some
nonoptimalities with this measure of partition quality,
and suggest some alternatives. Nonetheless, this measure is
commonly used, we will take this opportunity to note
its problems, and none of the techniques that we describe
is tied to this measure.
JAIR, 4