We do not discuss the Ring and Cube Center domains for CAltAlt because it cannot solve even the smallest instances. Due to implementation details the planner performs very poorly when domains have actions with several conditional effects and hence does not scale. The trouble stems from a weak implementation for bringing general propositional formulas (obtained by regression with several conditional effects) into CNF.
|
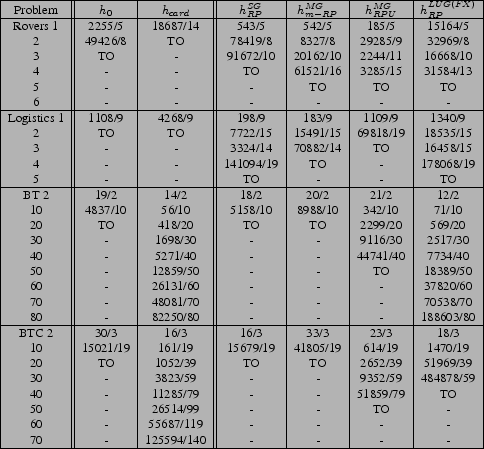
We describe the results from left to right in Table 3,
comparing the different planning graph structures and relaxed plans
computed on each planning graph. We start with the non-planning
graph heuristics ![]() and
and ![]() . As expected,
. As expected, ![]() ,
breadth-first search, does not perform well in a large portion of
the problems, shown by the large number of search nodes and
inability to scale to solve larger problems. We notice that with the
,
breadth-first search, does not perform well in a large portion of
the problems, shown by the large number of search nodes and
inability to scale to solve larger problems. We notice that with the
![]() heuristic performance is very good in the BT and BTC
problems (this confirms the results originally seen by
[2]). However,
heuristic performance is very good in the BT and BTC
problems (this confirms the results originally seen by
[2]). However, ![]() does not perform
as well in the Rovers and Logistics problems because the size of a
belief state, during planning, does not necessarily indicate that
the belief state will be in a good plan. Part of the reason
does not perform
as well in the Rovers and Logistics problems because the size of a
belief state, during planning, does not necessarily indicate that
the belief state will be in a good plan. Part of the reason
![]() works so well in some domains is that it measures
knowledge, and plans for these domains are largely based on
increasing knowledge. The reason
works so well in some domains is that it measures
knowledge, and plans for these domains are largely based on
increasing knowledge. The reason ![]() performs poorly on
other domains is that finding causal support (which it does not
measure) is more important than knowledge for these domains.
performs poorly on
other domains is that finding causal support (which it does not
measure) is more important than knowledge for these domains.
Next, for a single planning graph (![]() ), CAltAlt does
reasonably well with the
), CAltAlt does
reasonably well with the
![]() heuristic in the Rovers and
Logistics domains, but fails to scale very well on the BT and BTC
domains. Rovers and Logistics have comparatively fewer initial
worlds than the BT and BTC problems. Moreover the deterministic
plans, assuming each initial state is the real state, are somewhat
similar for Rovers and Logistics, but mostly independent for BT and
BTC. Therefore, approximating a fully observable plan with the
single graph relaxed plan is reasonable when plans for achieving the
goal from each world have high positive interaction. However,
without high positive interaction the heuristic degrades quickly
when the number of initial worlds increases.
heuristic in the Rovers and
Logistics domains, but fails to scale very well on the BT and BTC
domains. Rovers and Logistics have comparatively fewer initial
worlds than the BT and BTC problems. Moreover the deterministic
plans, assuming each initial state is the real state, are somewhat
similar for Rovers and Logistics, but mostly independent for BT and
BTC. Therefore, approximating a fully observable plan with the
single graph relaxed plan is reasonable when plans for achieving the
goal from each world have high positive interaction. However,
without high positive interaction the heuristic degrades quickly
when the number of initial worlds increases.
With multiple planning graphs, CAltAlt is able to perform better in the Rovers domain, but takes quite a bit of time in the Logistics, BT, and BTC domains. In Rovers, capturing distance estimates for individual worlds and aggregating them by some means tends to be better than aggregating worlds and computing a single distance estimate (as in a single graph). In Logistics, part of the reason computing multiple graphs is so costly is that we are computing mutexes on each of the planning graphs. In BT and BTC, the total time increases quickly because the number of planning graphs, and number of relaxed plans for every search node increase so much as problems get larger.
Comparing the two multiple graph heuristics6 in CAltAlt namely
![]() and
and
![]() , we can see the effect of our choices for state
distance aggregation. The
, we can see the effect of our choices for state
distance aggregation. The
![]() relaxed plan heuristic
aggregates state distances, as found on each planning graph, by
taking the maximum distance. The
relaxed plan heuristic
aggregates state distances, as found on each planning graph, by
taking the maximum distance. The
![]() unions the
relaxed plans from each graph, and counts the number of actions in
the unioned relaxed plan. As with the single graph relaxed plan,
the
unions the
relaxed plans from each graph, and counts the number of actions in
the unioned relaxed plan. As with the single graph relaxed plan,
the
![]() relaxed plan essentially measures one state to
state distance; thus, performance suffers on the BT and BTC
domains. However, using the unioned relaxed plan heuristic, we
capture the independence among the multiple worlds so that we
scale up better in BT and BTC. Despite the usefulness of the
unioned relaxed plan, it is costly to compute and scalability is
limited, so we turn to the
relaxed plan essentially measures one state to
state distance; thus, performance suffers on the BT and BTC
domains. However, using the unioned relaxed plan heuristic, we
capture the independence among the multiple worlds so that we
scale up better in BT and BTC. Despite the usefulness of the
unioned relaxed plan, it is costly to compute and scalability is
limited, so we turn to the ![]() version of this same measure.
version of this same measure.
With the ![]() , we use the
, we use the
![]() heuristic in CAltAlt.
This heuristic uses a
heuristic in CAltAlt.
This heuristic uses a ![]() with full cross-world mutexes (denoted
by
with full cross-world mutexes (denoted
by ![]() ). As in the similar
). As in the similar
![]() heuristic, measuring
overlap is important, and improving the speed of computing the
heuristic tends to improve the scalability of CAltAlt. While
CAltAlt is slower in the Rovers and BTC domains when using the
heuristic, measuring
overlap is important, and improving the speed of computing the
heuristic tends to improve the scalability of CAltAlt. While
CAltAlt is slower in the Rovers and BTC domains when using the
![]() , we note that it is because of the added cost of computing
cross-world mutexes - we are able to improve the speed by relaxing
the mutexes, as we will describe shortly.
, we note that it is because of the added cost of computing
cross-world mutexes - we are able to improve the speed by relaxing
the mutexes, as we will describe shortly.