Next: Random Problems with Added Up: Dual and Double Encodings Previous: Dual and Double Encodings
We first give some indicative results of a comparison between the various algorithms using random problems. Figure 7 compares the time that is required to enforce AC in the DE and GAC in the non-binary representation, while Figures 8-10 compare algorithms that maintain these consistencies.
Figure 7 shows the average cpu times (in msecs) that PW-AC and AC-2001 take to enforce AC in the DE of 100 random CSPs with 50 variables with domain size 30, ternary constraints, and 0.3 graph density (58 constraints). We also include the average time GAC-2001 takes to enforce GAC on the non-binary representation of the generated instances. The looseness of the constraints is varied starting from a point where all instances are not GAC up until GAC and AC in the DE do not delete any values. There is significant difference in the performance of PW-AC compared to AC-2001 which constantly rises as the looseness of the constraints becomes higher. This is expected, since as the number of allowed tuples in a constraint grows, AC-2001 takes more and more time to find supports. GAC-2001 is faster than PW-AC (up to one order of magnitude) when the looseness in low, but the difference becomes smaller as the looseness grows.
Figure 8 shows cpu times for a relatively sparse
class of problems with 30 variables and 40 ternary constraints
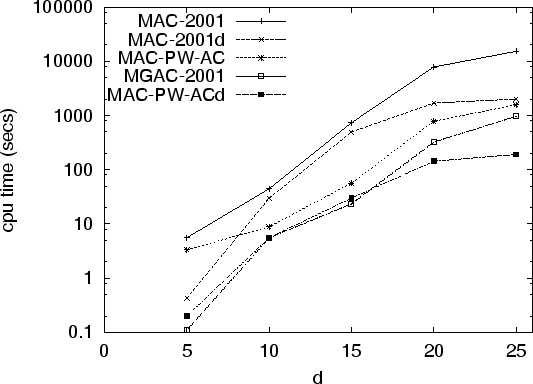
(![]() ). Figure 9 shows cpu times and node visits
for a denser class with 30 variables and 203 ternary constraints
(
). Figure 9 shows cpu times and node visits
for a denser class with 30 variables and 203 ternary constraints
(![]() ). Along the x-axis we vary the domain size of the
variables. All data points show average cpu times (in secs) over
100 instances taken from the hard phase transition region.
). Along the x-axis we vary the domain size of the
variables. All data points show average cpu times (in secs) over
100 instances taken from the hard phase transition region.
We can make the following observations: 1) MAC-PW-AC and
MAC-PW-ACd are significantly faster (one order of magnitude) than
MAC-2001 and MAC-2001d, respectively, in both classes of problems.
2) For both these classes, the non-binary representation is
preferable to the DE (MGAC-2001 is two orders of magnitude faster
in the denser class). In the sparser class, MAC in the double
encoding (i.e. algorithm MAC-PW-ACd) is competitive with MGAC-2001
for small domain sizes, and considerably faster for larger domain
sizes. The effect of the domain size in the relative performance
of the algorithms is mainly due to a run time advantage of PW-AC
compared to GAC-2001, and not to the higher consistency level
achieved in the double encoding7. The run time advantage of PW-AC can be
explained considering that, as the domain size increases, GAC-2001
has to check an increasing number of tuples for supports; an
operation more costly than the counter updates of PW-AC. In the
denser class MGAC-2001 is constantly faster than all the other
algorithms for all domain sizes. This is not surprising
considering the ![]() and
and
![]() complexities of PW-AC
and GAC-2001 (i.e. factor
complexities of PW-AC
and GAC-2001 (i.e. factor ![]() becomes more significant).
becomes more significant).
In Figure 10 we compare algorithms MGAC-2001 and MAC-PW-ACd (the faster among the algorithms for the encodings) in a class of problems with 20 variables and 48 4-ary constraints. The other algorithms for the encodings were not competitive in this class of problems. We can see that MGAC-2001 is more efficient for small domain sizes, while for larger domain sizes MAC-PW-ACd can be up to one order of magnitude faster. However, for denser classes of problems these results are reversed.
From our experiments with random problems we conjecture that the double encoding should be the preferred model for sparse problems, provided that an efficient algorithm like PW-AC is used for propagation. For CSPs with medium and high density the non-binary representation is preferable to the encodings.