The Exponential-family Principal Components Analysis model gives us a
way to find a low-dimensional representation of the beliefs that
occur in any particular problem. For the two real-world navigation
problems we have tried, the algorithm proved to be effective at
finding very low-dimensional representations, showing reductions from
![]() states and
states and
![]() states down to 5 or 6 bases.
A 5 or 6 dimensional belief space will allow much more tractable
computation of the value function, and so we will be able to solve
much larger POMDPs than we could have solved previously.
states down to 5 or 6 bases.
A 5 or 6 dimensional belief space will allow much more tractable
computation of the value function, and so we will be able to solve
much larger POMDPs than we could have solved previously.
Unfortunately, we can no longer use conventional POMDP value iteration to find the optimal policy given the low-dimensional set of belief space features. POMDP value iteration depends on the fact that the value function is convex over the belief space. When we compute a non-linear transformation of our beliefs to recover their coordinates on the low-dimensional belief surface, we lose the convexity of the value function (compare Figure 3 and Figure 6 to see why). As a result, the value function cannot be expressed as the supremum of a set of hyperplanes over the low-dimensional belief space.
So, instead of using POMDP value iteration, we will build a low-dimensional
discrete belief space MDP and use MDP value iteration. Since we do not know
the form of the value function, we will turn to function approximation.
Gordon [Gor95] proved that the fitted value iteration algorithm
is guaranteed to find a bounded-error approximation to a (possibly discounted)
MDP's value function, so long as we use it in combination with a function
approximator that is an averager. Averagers are function approximators
which are non-expansions in max-norm; that is, they do not exaggerate errors
in their training data. In our experiments below, we use regular grids as well
as irregular, variable-resolution grids based on ![]() -nearest-neighbour
discretization, represented by a set of low-dimensional beliefs
-nearest-neighbour
discretization, represented by a set of low-dimensional beliefs
![]() ,
,
| (29) |
The fitted value iteration algorithm uses the following update rule to
compute a ![]() -step lookahead value function
-step lookahead value function ![]() from a
from a ![]() -step
lookahead value function
-step
lookahead value function ![]() :
:
The original reward function ![]() represents the immediate reward
of taking action
represents the immediate reward
of taking action ![]() at state
at state ![]() . We cannot know, given either
a low-dimensional or high-dimensional belief, what the immediate
reward will be, but we can compute the expected
reward. We therefore represent the reward as the expected value of the
immediate reward of the full model, under the current belief:
. We cannot know, given either
a low-dimensional or high-dimensional belief, what the immediate
reward will be, but we can compute the expected
reward. We therefore represent the reward as the expected value of the
immediate reward of the full model, under the current belief:
For many problems, the reward function
![]() will have the effect of
giving a low immediate reward for belief states with high entropy. That is,
for many problems the planner will be driven towards beliefs that are centred
on high-reward states and have low uncertainty. This property is intuitively
desirable: in such beliefs the robot does not have to worry about an immediate
bad outcome.
will have the effect of
giving a low immediate reward for belief states with high entropy. That is,
for many problems the planner will be driven towards beliefs that are centred
on high-reward states and have low uncertainty. This property is intuitively
desirable: in such beliefs the robot does not have to worry about an immediate
bad outcome.
Computing the low-dimensional transition function
![]() is not as simple as computing the
low-dimensional reward function
is not as simple as computing the
low-dimensional reward function
![]() : we need to
consider pairs of low-dimensional beliefs,
: we need to
consider pairs of low-dimensional beliefs,
![]() and
and
![]() . In the original high-dimensional belief space, the
transition from a prior belief
. In the original high-dimensional belief space, the
transition from a prior belief ![]() to a posterior belief
to a posterior belief ![]() is
described by the Bayes filter equation:
is
described by the Bayes filter equation:
Equation (33) describes a deterministic transition conditioned upon a
prior belief, an action and an observation. The transition to the
posterior ![]() is stochastic when the observation is not known; that
is, the transition from
is stochastic when the observation is not known; that
is, the transition from ![]() to
to ![]() occurs only when a specific
occurs only when a specific ![]() is generated, and the probability of this transition is the
probability of generating observation
is generated, and the probability of this transition is the
probability of generating observation ![]() . So, we can separate the
full transition process into a deterministic transition to
. So, we can separate the
full transition process into a deterministic transition to ![]() , the
belief after acting but before sensing, and a stochastic transition to
, the
belief after acting but before sensing, and a stochastic transition to
![]() , the full posterior:
, the full posterior:
Equations 34 and 35 describe the transitions of the high-dimensional beliefs for the original POMDP. Based on these high-dimensional transitions, we can compute the transitions in our low-dimensional approximate belief space MDP. Figure 14 depicts the process.
As the figure shows, we start with a low-dimensional belief
If our function approximator is a grid, the last step above means replacing
![]() by a prototypical
by a prototypical
![]() which shares its grid cell.
More generally, our function approximator may represent
which shares its grid cell.
More generally, our function approximator may represent
![]() as a
combination of several states, putting weight
as a
combination of several states, putting weight
![]() on each
on each
![]() . (For example, if our approximator is
. (For example, if our approximator is
![]() -nearest-neighbour,
-nearest-neighbour,
![]() for each of
the closest
for each of
the closest ![]() samples in
samples in
![]() .) In this case we replace the
transition from
.) In this case we replace the
transition from
![]() to
to
![]() with several transitions,
each from
with several transitions,
each from
![]() to some
to some
![]() , and scale the probability
of each one by
, and scale the probability
of each one by
![]() .
.
For each transition
![]() we can assign a probability
we can assign a probability
With the reward and transition functions computed in the previous sections, we can use value iteration to compute the value function for our belief space MDP. The full algorithm is given in Table 2.




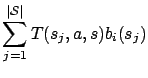
![\includegraphics[height=1.5in]{figs/process.eps}](img189.png)
