Next: Appendix B: Efficient Action Up: Reinforcement Learning for Agents Previous: Acknowledgments
In this appendix, we describe in detail the approach described in the main body of the paper.
 |
The partial-rule learning algorithm (whose top level form is shown in Figure 11) stores the following information for each partial rule
To estimate the confidence on ![]() and
and ![]() we use a
confidence index
we use a
confidence index ![]() that, roughly speaking, keeps track of the number of times the partial
rule is used. The confidence is derived
from
that, roughly speaking, keeps track of the number of times the partial
rule is used. The confidence is derived
from ![]() using a confidence_function in the following way:
using a confidence_function in the following way:
Additionally, the confidence index is used to define the learning rate (i.e., the weight of new observed rewards in the statistics update). For this purpose we implement a MAM function [Venturini, 1994] for each rule:
Using a MAM-based updating rule, we have that, the lower the confidence, the higher the effect of the last observed rewards on the statistics, and the faster the adaptation of the statistics. This adaptive learning rate strategy is related to those presented by [Sutton, 1991] and by [Kaelbling, 1993], and contrasts with traditional reinforcement-learning algorithms where a constant learning rate is used.
After the initialization phase, the algorithm enters in a continuous loop for each task episode consisting in estimating the possible effects of all actions, executing the most promising one, and updating the system so that its performance improves in the future. The system update includes the statistics update and the partial-rule management.
The simplest procedure to get the estimated value for actions is a brute-force approach consisting of the independent evaluation of each one of them. In simple cases, this approach would be enough but, when the number of valid combinations of elementary actions (i.e., of actions) is large, the separate evaluation of each action would take long time, increasing the time of each robot decision and decreasing the reactivity of the control. To avoid this, Appendix B presents a more efficient procedure to get the value of any action.
Figure 13 summarizes the action-evaluation procedure using partial rules. The value for each action is guessed using the most relevant rule for this action (i.e., the winner rule). This winner rule is computed as
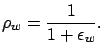 |
The value estimation using the winner rule is selected at random (uniformly) from the interval
In the statistics-update procedure (Figure 14), ![]() and
and
![]() are adjusted
for all rules that were active in the previous time step and proposed a partial command in
accordance with
are adjusted
for all rules that were active in the previous time step and proposed a partial command in
accordance with ![]() (the last executed action).
(the last executed action).
Both ![]() and
and ![]() are updated using a learning rate (
are updated using a learning rate (![]() ) computed using the MAM function,
which initially is 1, and consequently, the initial values of
) computed using the MAM function,
which initially is 1, and consequently, the initial values of ![]() and
and
![]() have no influence on the future values of these variables. These initial values become
relevant when using a constant learning rate, as many existing reinforcement-learning
algorithms do.
have no influence on the future values of these variables. These initial values become
relevant when using a constant learning rate, as many existing reinforcement-learning
algorithms do.
If the observed effects of the last executed action agree with the current estimated interval
for the value (![]() ), then the confidence index is increased by one unit. Otherwise, the
confidence index is decreased allowing a faster adaptation of the statistics to the last
obtained, surprising values of reward.
), then the confidence index is increased by one unit. Otherwise, the
confidence index is decreased allowing a faster adaptation of the statistics to the last
obtained, surprising values of reward.
This procedure (Figure 15) includes the generation of new partial rules and the removal of previously generated ones that proved to be useless.
In our
implementation, we apply a heuristic that produces the generation of new partial rules when the
value prediction error exceeds
![]() . In this way, we concentrate our efforts to
improve the categorization on those situations with larger errors in the value prediction.
. In this way, we concentrate our efforts to
improve the categorization on those situations with larger errors in the value prediction.
Every time a wrong prediction is made, at most ![]() new partial rules are generated by
combination of pairs of rules included in the set
new partial rules are generated by
combination of pairs of rules included in the set
![]() . Recall that this set
includes the rules active in the previous time step and in accordance with the executed action
. Recall that this set
includes the rules active in the previous time step and in accordance with the executed action ![]() .
Thus, these are the rules related with the situation-action whose
value prediction we need to improve.
.
Thus, these are the rules related with the situation-action whose
value prediction we need to improve.
The combination of two partial rules
![]() consists of a new
partial rule with a partial view that includes all the features included in the partial views
of either
consists of a new
partial rule with a partial view that includes all the features included in the partial views
of either ![]() or
or ![]() and with a partial command that includes all the elementary actions
of the partial commands of either
and with a partial command that includes all the elementary actions
of the partial commands of either ![]() or
or ![]() .
In other words, the feature set of
.
In other words, the feature set of
![]() is the union of the feature sets in
is the union of the feature sets in
![]() and in
and in ![]() and the elementary actions in
and the elementary actions in
![]() are
the union of those in
are
the union of those in ![]() and those in
and those in ![]() . Note that, since both
. Note that, since both ![]() and
and ![]() are in
are in
![]() , they have been simultaneously active and they are in accordance
with the same action and, thus, they can not be incompatible (i.e., they can not include
inconsistent features or elementary actions).
, they have been simultaneously active and they are in accordance
with the same action and, thus, they can not be incompatible (i.e., they can not include
inconsistent features or elementary actions).
 |
In the partial-rule creation, we bias our system to favor the combination of those rules (![]() )
whose value prediction (
)
whose value prediction (![]() ) is closer to the observed one (
) is closer to the observed one (![]() ). Finally, the
generation of rules lexicographically equivalent to already existing ones is not
allowed.
). Finally, the
generation of rules lexicographically equivalent to already existing ones is not
allowed.
According to the categorizability assumption, only low-order partial rules are required to
achieve the task at hand. For this reason, to improve efficiency, we limit the number of
partial rules to a maximum of ![]() . However, our partial-rule generation procedure is always
generating new rules (concentrating on those situations with larger error). Therefore, when we
need to create new rules and there is no room for them, we must eliminate the less useful
partial rules.
. However, our partial-rule generation procedure is always
generating new rules (concentrating on those situations with larger error). Therefore, when we
need to create new rules and there is no room for them, we must eliminate the less useful
partial rules.
A partial rule can be removed if its value prediction is too similar to some other rule in the same situations.
The similarity between two rules can be measured using the normalized degree of intersection between their value distributions and the number of times both rules are used simultaneously:
 |
The
similarity assessment
for any pair of partial rules in the controller is too expensive and, in general,
determining the similarity of each rule with respect to those from which it was generated
(that are the rules we tried to refine when the new rule was created) is sufficient.
Thus, based on the above similarity measure, we define the redundancy of a partial
rule
![]() as:
as:
Observe that with
![]() , we have that
, we have that
![]() and
and
![]() . Therefore
. Therefore
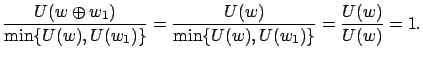 |
 |
When we need to create new rules but the maximum number of rules (![]() ) has been
reached, the partial rules with a redundancy above a
given threshold (
) has been
reached, the partial rules with a redundancy above a
given threshold (![]() ) are eliminated. Since the redundancy of a partial rule can only be
estimated after observing it a number of times, the redundancy of the partial rules with low
confidence indexes are set to 0, so that they are not immediately removed after creation.
) are eliminated. Since the redundancy of a partial rule can only be
estimated after observing it a number of times, the redundancy of the partial rules with low
confidence indexes are set to 0, so that they are not immediately removed after creation.
Observe that, to compute the redundancy of a rule ![]() , we use the partial rules from which
, we use the partial rules from which
![]() was derived. For this reason, a rule
was derived. For this reason, a rule ![]() cannot be removed from a controller
cannot be removed from a controller ![]() if
there exists any rule
if
there exists any rule ![]() such that
such that
![]() . Additionally, in this way we eliminate first
the useless rules with higher order.
. Additionally, in this way we eliminate first
the useless rules with higher order.
Josep M Porta 2005-02-17
![\includegraphics[width=0.7\linewidth]{images/figure_jair_10}](img190.png)

