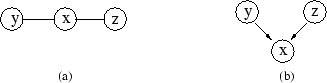The search procedures used within Bayesian network learning algorithms usually operate on the space of DAGs. In this context, the problem can be formally expressed as: Given a complete training set (i.e. we do not consider missing values or latent variables)
![]() of instances of a finite set of
of instances of a finite set of ![]() variables,
variables, ![]() , find the DAG
, find the DAG ![]() such that
such that
| (1) |
Many of the search procedures, including the commonly used local search methods, rely on a neighborhood structure that defines the local rules (operators) used to move within the search space. The standard neighborhood in the space of DAGs uses the operators of arc addition, arc deletion and arc reversal, thereby avoiding (in the first and the third case) the inclusion of directed cycles in the graph.
The algorithms that search in the space of DAGs using local methods are efficient mainly because of the decomposability property that many scoring functions exhibit. A scoring function ![]() is said to be decomposable if the score of any Bayesian network structure may be expressed as a product (or a sum in the log-space) of local scores involving only one node and its parents:
is said to be decomposable if the score of any Bayesian network structure may be expressed as a product (or a sum in the log-space) of local scores involving only one node and its parents:
A procedure that changes one arc at each move can efficiently evaluate the improvement obtained by this change. Such a procedure can reuse the computations carried out at previous stages, and only the statistics corresponding to the variables whose parent sets have been modified need to be recomputed. The addition or deletion of an arc
![]() in a DAG
in a DAG ![]() can therefore be evaluated by computing only one new local score,
can therefore be evaluated by computing only one new local score,
![]() or
or
![]() , respectively. The evaluation of the reversal of an arc
, respectively. The evaluation of the reversal of an arc
![]() requires the computation of two new local scores,
requires the computation of two new local scores,
![]() and
and
![]() .
.
It should be noted that each structure in the DAG space is not always different from the others in terms of its representation capability: if we interpret the arcs in a DAG as causal interactions between variables, then each DAG represents a different model; however, if we see a DAG as a set of dependence/independence relationships between variables (that permits us to factorize a joint probability distribution), then different DAGs may represent the same model. Even in the case of using a causal interpretation, if we use observation-only data (as opposed to experimental data where some variables may be manipulated), it is quite common for two Bayesian networks to be empirically indistinguishable. When two DAGs ![]() and
and ![]() can represent the same set of conditional independence assertions, we say that these DAGs are equivalent3 [59], and we denote this as
can represent the same set of conditional independence assertions, we say that these DAGs are equivalent3 [59], and we denote this as ![]() .
.
When learning Bayesian networks from data using scoring functions, two different (but equivalent) DAGs may be indistinguishable, due to the existence of invariant properties on equivalent DAGs, yielding equal scores. We could take advantage of this in order to get a more reduced space of structures to be explored.
The following theorem provides a graphical criterion for determining the equivalence of two DAGs:
Another characterization of equivalent DAGs was presented by [15], together with proof that several scoring functions used for learning Bayesian networks from data give the same score to equivalent structures (such functions are called score equivalent functions).
The concept of equivalence of DAGs partitions the space of DAGs into a set of equivalence classes. Whenever a score equivalent function is used, it seems natural to search for the best configuration in this new space of equivalence classes of DAGs. This change in the search space may bring several advantages:
The disadvantages are that, in this space of equivalence classes, it is more expensive to generate neighboring configurations, because we may be forced to perform some kind of consistency check, in order to ensure that these configurations represent equivalence classes4; in addition, the evaluation of the neighboring configurations may also be more expensive if we are not able to take advantage of the decomposability property of the scoring function. Finally, the new search space might introduce new local maxima that are not present in DAG space.
In order to design an exploring process for the space of equivalence classes we could use two distinct approaches: the first consists in considering that an equivalence class is represented by any of its components (in this case, it is necessary to avoid evaluating more than one component per class); and the second consists in using a canonical representation scheme for the classes.
The graphical objects commonly used to represent equivalence classes of DAGs are acyclic partially directed graphs [59] (known as PDAGs). These graphs contain both directed (arcs) and undirected (links) edges, but no directed cycles. Given a PDAG ![]() defined on a finite set of nodes
defined on a finite set of nodes ![]() and a node
and a node ![]() , the following subsets of nodes are defined:
, the following subsets of nodes are defined:
Note that an arbitrary PDAG does not necessarily represent some equivalence class of DAGs, although there is a one-to-one correspondence between completed PDAGs and equivalence classes of DAGs. Nevertheless, completed PDAGs are considerably more complicated than general PDAGs. A characterization of the specific properties that a PDAG must verify in order to be a completed PDAG was obtained by [4]:
Let us illustrate the advantages of searching in the space of equivalence classes of DAGs rather than the space of DAGs with a simple example. Figure 3 displays the set of possible DAGs involving three nodes ![]() , with arcs between
, with arcs between ![]() and
and ![]() , and between
, and between ![]() and
and ![]() . The first three DAGs are equivalent. In terms of independence information, they lead to the same independence statement
. The first three DAGs are equivalent. In terms of independence information, they lead to the same independence statement ![]() (
(![]() and
and ![]() are conditionally independent given
are conditionally independent given ![]() ), whereas the statement
), whereas the statement
![]() (
(![]() and
and ![]() are marginally independent) corresponds to the fourth one. The four DAGs may be summarized by only two different completed PDAGs, shown in Figure 4.
are marginally independent) corresponds to the fourth one. The four DAGs may be summarized by only two different completed PDAGs, shown in Figure 4.
As we can see, the search space may be reduced by using PDAGs to represent the classes: in our example, to two classes instead of four configurations; it can be seen [4] that the ratio of the number of DAGs to the number of classes is ![]() for three nodes,
for three nodes, ![]() for four nodes and
for four nodes and
![]() for five nodes; in more general terms, the results obtained by [39] indicate that this ratio approaches a value of less than four as the number of nodes increases. The use of equivalence classes therefore entails convenient savings in exploration and evaluation effort, although the gain is not spectacular.
for five nodes; in more general terms, the results obtained by [39] indicate that this ratio approaches a value of less than four as the number of nodes increases. The use of equivalence classes therefore entails convenient savings in exploration and evaluation effort, although the gain is not spectacular.
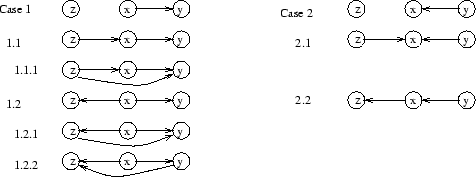
On the other hand, the use of a canonical representation scheme allows us to explore the space progressively and systematically, without losing any unexplored configuration unnecessarily. Returning to our example, let us suppose that the true model is the DAG displayed in Figure 4.b and we start the search with an empty graph (with no arcs). Let us also assume that the search algorithm identifies that an edge between ![]() and
and ![]() produces the greatest improvement in the score. At this moment, the two alternatives,
produces the greatest improvement in the score. At this moment, the two alternatives,
![]() and
and ![]() (case 1 and case 2 in Figure 5, respectively), are equivalent. Let us now suppose that we decide to connect the nodes
(case 1 and case 2 in Figure 5, respectively), are equivalent. Let us now suppose that we decide to connect the nodes ![]() and
and ![]() ; again we have two options:
; again we have two options:
![]() or
or ![]() . Nevertheless, depending on the previous selected configuration, we obtain different outcomes that are no longer equivalent (see Figure 5).
. Nevertheless, depending on the previous selected configuration, we obtain different outcomes that are no longer equivalent (see Figure 5).
If we had chosen case 1 (thus obtaining either case 1.1 or case 1.2), we would have eliminated the possibility of exploring the DAG
![]() , and therefore the exploring process would have been trimmed. As the true model is precisely this DAG (case 2.1 in Figure 5), then the search process would have to include another arc connecting
, and therefore the exploring process would have been trimmed. As the true model is precisely this DAG (case 2.1 in Figure 5), then the search process would have to include another arc connecting ![]() and
and ![]() (cases 1.1.1, 1.2.1 or 1.2.2), because
(cases 1.1.1, 1.2.1 or 1.2.2), because ![]() and
and ![]() are conditionally dependent given
are conditionally dependent given ![]() . At this moment, any local search process would stop (in a local optimum), because every local change (arc reversal or arc removal) would make the score worse.
. At this moment, any local search process would stop (in a local optimum), because every local change (arc reversal or arc removal) would make the score worse.
Consequently, our purpose consists in adding or removing edges (either links or arcs) to the structure without pruning the search space unnecessarily. We could therefore introduce links instead of arcs (when there is not enough information to distinguish between different patterns of arcs), which would serve as templates or dynamic linkers to equivalence patterns. They represent any valid combination of arcs which results in a DAG belonging to the same equivalence class.
Looking again at the previous example, we would proceed as follows: assuming that in our search space the operators of link addition and creation of h-h patterns are available, we would first include the link ![]() ; secondly, when considering the inclusion of a connection between
; secondly, when considering the inclusion of a connection between ![]() and
and ![]() , we would have two options, shown in Figure 4: the h-h pattern
, we would have two options, shown in Figure 4: the h-h pattern
![]() and the pattern
and the pattern
![]() . In this case the scoring function would assign the greatest score to the h-h pattern
. In this case the scoring function would assign the greatest score to the h-h pattern
![]() , thus obtaining the correct DAG.
, thus obtaining the correct DAG.