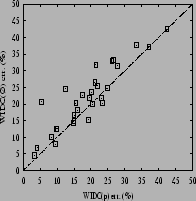
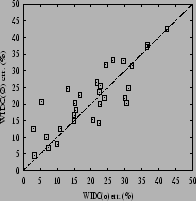
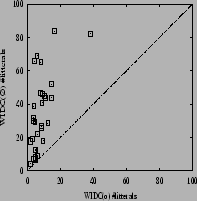
Experiments were carried out using three variants of WIDC: with optimistic pruning (o), with pessimistic pruning (p), and without pruning (![]() ). Table 1 presents some results on various datasets, most of which were taken from the UCI repository of machine learning database [Blake et al.1998]. For each dataset, the eventual discretization of attributes was performed following previous recommendations and experimental setups [de Carvalho Gomes Gascuel1994]. The results were computed using a ten-fold stratified cross validation procedure [Quinlan1996]. The least errors for WIDC are underlined for each domain. For the sake of comparisons, column ``Others'' points out various results for other algorithms, intended to help getting a general picture of what can be the performances of efficient approaches with different outputs (decision lists, trees, committees, etc.), in terms of errors (and, when applicable, sizes). Some of the most relevant results for WIDC are summarized in the scatterplots of Table 2.
). Table 1 presents some results on various datasets, most of which were taken from the UCI repository of machine learning database [Blake et al.1998]. For each dataset, the eventual discretization of attributes was performed following previous recommendations and experimental setups [de Carvalho Gomes Gascuel1994]. The results were computed using a ten-fold stratified cross validation procedure [Quinlan1996]. The least errors for WIDC are underlined for each domain. For the sake of comparisons, column ``Others'' points out various results for other algorithms, intended to help getting a general picture of what can be the performances of efficient approaches with different outputs (decision lists, trees, committees, etc.), in terms of errors (and, when applicable, sizes). Some of the most relevant results for WIDC are summarized in the scatterplots of Table 2.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The interpretation of Table 1 using only errors gives the advantage to WIDC with pessimistic pruning, all the more as WIDC(p) has the advantage of providing simpler formulas than WIDC(![]() ), and has a much simpler pruning stage than WIDC(o). Results also compare favorably to the ``Other'' results, building either DLs, DTs, or DCs. They are all the more interesting if we compare the errors in the light of the sizes obtained. For the ``Echo'' domain, WIDC with
pessimistic pruning beats improved CN2 by two points, but the DC obtained
contains roughly eight times fewer literals than CN2-POE's decision list. If we
except ``Vote0'', on all other problems on which we dispose of CN2-POE's results, we outperform CN2-POE on both
accuracy and size. Finally, on ``Vote0'', note that WIDC with optimistic
pruning is slightly outperformed by CN2-POE by
), and has a much simpler pruning stage than WIDC(o). Results also compare favorably to the ``Other'' results, building either DLs, DTs, or DCs. They are all the more interesting if we compare the errors in the light of the sizes obtained. For the ``Echo'' domain, WIDC with
pessimistic pruning beats improved CN2 by two points, but the DC obtained
contains roughly eight times fewer literals than CN2-POE's decision list. If we
except ``Vote0'', on all other problems on which we dispose of CN2-POE's results, we outperform CN2-POE on both
accuracy and size. Finally, on ``Vote0'', note that WIDC with optimistic
pruning is slightly outperformed by CN2-POE by ![]() , but the DC obtained
is fifteen times smaller than the decision list of CN2-POE. If we dwell on the results of C4.5,
similar conclusions can be brought: on 12 out of 13 datasets on which we ran C4.5, WIDC(p) finds smaller
formulas, and still beats C4.5's accuracy on 9 of them. A quantitative comparison of
, but the DC obtained
is fifteen times smaller than the decision list of CN2-POE. If we dwell on the results of C4.5,
similar conclusions can be brought: on 12 out of 13 datasets on which we ran C4.5, WIDC(p) finds smaller
formulas, and still beats C4.5's accuracy on 9 of them. A quantitative comparison of ![]() against the number of nodes of the DTs shows that on 4 datasets out of the 13 (Pole, Shuttle, TicTacToe, Australian),
the DCs are more than 6 times smaller, while they only incur a loss in accuracy for 2 of them, and limited to 1.8
against the number of nodes of the DTs shows that on 4 datasets out of the 13 (Pole, Shuttle, TicTacToe, Australian),
the DCs are more than 6 times smaller, while they only incur a loss in accuracy for 2 of them, and limited to 1.8![]() .
For this latter problem (TicTacToe), a glimpse at Table 1 shows that the DCs, with less than 7 rules
on average, keeps comparatively most of the information contained in DTs having more than a hundred leaves. On many
problems where mining issues are crucial, such a size reduction would be well worth the (comparatively slight) loss in
accuracy, because we keep a significant part of the information on very small classifiers, thus likely to be interpretable.
.
For this latter problem (TicTacToe), a glimpse at Table 1 shows that the DCs, with less than 7 rules
on average, keeps comparatively most of the information contained in DTs having more than a hundred leaves. On many
problems where mining issues are crucial, such a size reduction would be well worth the (comparatively slight) loss in
accuracy, because we keep a significant part of the information on very small classifiers, thus likely to be interpretable.