Our experiments apply the machine learning program RIPPER [CohenCohen1995,CohenCohen1996] to automatically classify the dialogues as problematic or successful. RIPPER is a fast and efficient rule learning system described in more detail in [CohenCohen1995,CohenCohen1996]; we describe it briefly here for completeness. RIPPER is based on the incremental reduced error pruning (IREP) algorithm described in [Furnkranz WidmerFurnkranz Widmer1994]. RIPPER improves on IREP with an information gain metric to guide rule pruning and a Minimum Description Length or MDL-based heuristic for determining how many rules should be learned (see Cohen 1995, 1996 for more details). Like other learners, RIPPER takes as input the names of a set of classes to be learned, the names and ranges of values of a fixed set of features, and training data specifying the class and feature values for each example in a training set. Its output is a classification model for predicting the class of future examples, expressed as an ordered set of if-then rules.
Although any one of a number of learners could be applied to this problem, we had a number of reasons for choosing RIPPER. First, it was important to be able to integrate the results of applying the learner back into the HMIHY spoken dialogue system. Previous work suggests that the if-then rules that RIPPER uses to express the learned classification model are easy for people to understand [CatlettCatlett1991,CohenCohen1995], making it easier to integrate the learned rules into the HMIHY system. Second, RIPPER supports continuous, symbolic and textual bag (set) features [CohenCohen1996], while other learners, such as Classification and Regression trees (CART) [Brieman, Friedman, Olshen, StoneBrieman et al.1984], do not support textual bag features. There are several textual features in this dataset that prove useful in classifying the dialogues. One of the features that we wished to use was the string representing the recognizer's hypothesis. This is supported in RIPPER because there is no a priori limitation on the size of the set. The usefulness of the textual features is exemplified in Section 6.3. Finally, previous work in which we had applied other learners to the auto-SLU-success predictor, utilizing the best performing feature set with the textual bag features removed, suggested that we could not expect any significant performance improvements from using other learners [Walker, Wright, LangkildeWalker et al.2000c].
In order to train the problematic dialogue predictor (PDP), RIPPER uses a set of features. As discussed above, initial experiments showed that the hand-labelled SLU-success feature, which encodes whether an utterance has been misunderstood or not, is highly discriminatory in identifying problematic dialogues. However, all the features used to train the PDP must be totally automatic if we are to use the PDP in a working spoken dialogue system. In order to improve the performance of the fully automatic PDP, we developed a fully automatic approximation of the hand-labelled feature, which we call the auto-SLU-success feature, in separate experiments with RIPPER. The training of the auto-SLU-success feature is discussed in Section 5.
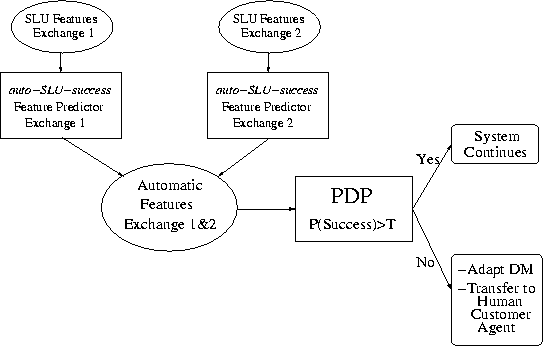
Evidence from previous trials of HMIHY suggest that it is important to identify problems within a couple of exchanges and 97% of the dialogues in the corpus are five exchanges or less. Thus features for the first two exchanges are encoded since the goal is to predict failures before they happen. The experimental architecture of the PDP is illustrated in Figure 5. This shows how RIPPER is used first to predict auto-SLU-success for the first and second exchanges. This feature is fed into the PDP along with the other automatic features. The output of the PDP determines whether the system continues, or if a problem is predicted, the Dialogue Manager may adapt its dialogue strategy or transfer the customer to a customer agent.
Since 23% of the dialogues consisted of only two exchanges, we exclude the second exchange features for those dialogues where the second exchange consists only of the system playing a closing prompt. We also excluded any features that indicated to the classifier that the second exchange was the last exchange in the dialogue. We compare results for predicting problematic dialogues, with results for identifying problematic dialogues, when the classifier has access to features representing the whole dialogue.
In order to test the auto-SLU-success predictor as input to the PDP, we first defined a training and test set for the combined problem. The test set for the auto-SLU-success predictor contains the exchanges that occur in the dialogues of the PDP test set. We selected a random 867 dialogues as the test set and then extracted the corresponding exchanges (3829 exchanges). Similarly for training, the PDP training set contains 3825 dialogues which corresponds to a total of 16901 exchanges for training the auto-SLU-success predictor.
The feature auto-SLU-success is predicted for each utterance in the test set, thus enabling the system to be used on new data without the need for hand-labelling. However, there are two possibilities for the origin of this feature in the training set. The first possibility is for the training set to also consist of solely automatic features. This method has the potential advantage that the trained PDP will compensate, if necessary, for whatever noise exists in the auto-SLU-success predictions [WrightWright2000]. An alternative to training the PDP on the automatically derived auto-SLU-success feature is to train it on the hand-labelled SLU-success while still testing it on the automatic feature. This second method is referred to as ``hand-labelled-training'' or hlt-SLU-success. This may provide a more accurate model but it may not capture the characteristics of the automatic feature in the test set. Results for these two methods are presented in Section 6.4.
The problem with using auto-SLU-success for training the PDP is that the same data is used to train the auto-SLU-success predictor. Therefore, we used a cross-validation technique (also known as jack-knifing) [Weiss KulikowskiWeiss Kulikowski1991], whereby the training set is partitioned into 4 sets. Three of these sets are used for training and the fourth for testing. The results for the fourth set are noted and the process is repeated, rotating the sets from training to testing. This results in a complete list of predicted auto-SLU-success for the training set. The features for the test set exchanges are derived by training RIPPER on the whole training set. This process is illustrated in Figure 6.
The following section gives a breakdown of the input features. Section 5 describes the training and results of the auto-SLU-success predictor and Section 6 reports the accuracy results for the PDP.