The third experiment investigates the time taken to learn in a new, but related, environment in the robot navigation domain. Nine different inner rooms were generated randomly, again under some constraints. All have a single doorway, but the size and position of the room and the location of the doorway are varied as shown in Figure 30. To initialize the case base, a function is learned for each of these configurations with the goal inside the small room as indicate by the dark square. Learning is then repeated on each of the room configurations in turn. However, when composing the new function the system is prevented from selecting a case learned from the same goal and room configuration. Experimental runs for the Q-learning algorithm and the function composition system are initialized with a flat function of zero and 0.75 everywhere respectively, denoted as zero on the x-axis. Learning continues for 100,000 steps. To improve the statistical variation, experiments for each configuration were repeated three times, each time with a new random seed. The curves in Figure 31 are, therefore, the average across 27 experimental runs.

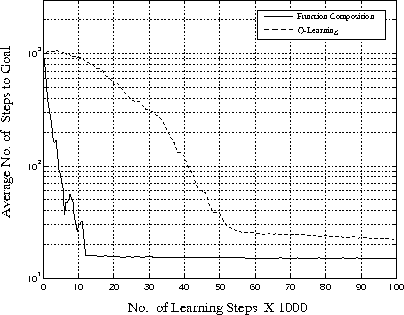
The top curve is the Q-learning algorithm, the bottom curve the function composition system. For these experiments, locating the goal took typically between 400 and 1200 steps, although some took 2000 steps. The function composition system then introduces the ``no walls'' function and typically a further 800 to 4000 steps are taken before usable features are generated. Again, certain experimental runs took longer, this will be discussed in Section 5.2. Due to these runs, the knee of the function composition system's curve occurs at 12,000 steps. The knee of the basic Q-learning curve occurs at approximately 54,000 steps giving a speed up of 4.5. As in previous experiments once initialized the function is very accurate and little further refinement is necessary. Basic Q-learning, on reaching the knee, takes a long time to remove the residual error.