Query Planning is a problem of considerable practical importance. It is central to traditional database and mediator systems. In this section we present some results in distributed query planning to highlight the use of PbR in a domain with a complex cost function. A detailed description of query planning, including a novel query processing algorithm for mediators based on PbR, and a more extensive experimental analysis appear in [5,3].
Query planning involves generating a plan that efficiently computes a user query from the relevant information sources. This plan is composed of data retrieval actions at distributed information sources and data manipulation operations, such as those of the relational algebra: join, selection, union, etc. The specification of the operators for query planning and the encoding of information goals that we are using was first introduced by Knoblock [49]. A sample information goal is shown in Figure 27. This goal asks to send to the output device of the mediator all the names of airports in Tunisia. Two sample operators are shown in Figure 28. The retrieve operator executes a query at a remote information source and transports the data to the mediator, provided that the source is in operation (source-available) and that the source is capable of processing the query (source-acceptable-query). The join operator takes two subqueries, which are available locally at the mediator, and combines them using some conditions to produce the joined query.
The quality of a distributed query plan is an estimation of its execution cost, which is a function of the size of intermediate results, the cost of performing data manipulation operations, and the transmission through the network of the intermediate results from the remote sources to the mediator. Our system estimates the plan cost based on statistics obtained from the source relations, such as the number of tuples in a relation, the number of distinct values for each attribute, and the maximum and minimum values for numeric attributes [76, chapter 12]. The sources accessed, and the type and ordering of the data processing operations are critical to the plan cost.
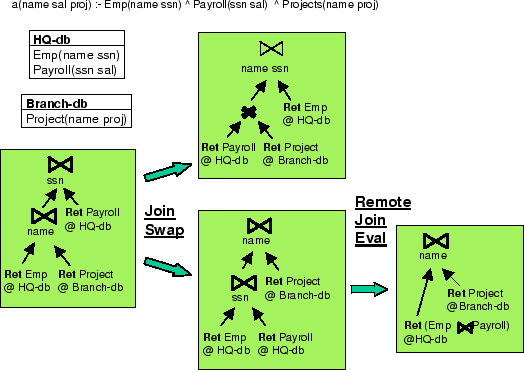
The rewriting rules are derived from properties of the distributed environment and the relational algebra.15 The first set of rules rely on the fact that, in a distributed environment, it is generally more efficient to execute a group of operations together at a remote information source than to transmit the data over the network and execute the operations at the local system. As an example consider the Remote-Join-Eval rule in Figure 29 (shown here in the PbR syntax, it was shown algebraically in Figure 1). This rule specifies that if in a plan there exist two retrieval operations at the same remote database whose results are consequently joined and the remote source is capable of performing joins, the system can rewrite the plan into one that contains a single retrieve operation that pushes the join to the remote database.
|
The second class of rules are derived from the commutative, associative, and distributive properties of the operators of the relational algebra. For example, the Join-Swap rule of Figure 29 (cf. Figure 1) specifies that two consecutive joins operators can be reordered and allows the planner to explore the space of join trees. Since in our query planning domain queries are expressed as complex terms [49], the PbR rules use the interpreted predicates in the :constraints field to manipulate such query expressions. For example, the join-swappable predicate checks if the queries in the two join operators can be exchanged and computes the new subqueries.
Figure 30 shows an example of the local search through the space of query plan rewritings in a simple distributed domain that describes a company. The figure shows alternative query evaluation plans for a conjunctive query that asks for the names of employees, their salaries, and the projects they are working on. The three relations requested in the query (Employees, Payroll, and Project) are distributed among two databases (one at the company's headquarters - HQ-db - and another at a branch - Branch-db). Assume that the leftmost plan is the initial plan. This plan first retrieves the Employee relation at the HQ-db and the Project relation at the Branch-db, and then it joins these two tables on the employee name. Finally, the plan retrieves the Payroll relation from the HQ-db and joins it on ssn with the result of the previous join. Although a valid plan, this initial plan is suboptimal. Applying the join-swap rule to this initial plan generates two rewritings. One of them involves a cross-product, which is a very expensive operation, so the system, following a gradient descent search strategy, prefers the other plan. Now the system applies the remote-join-eval rule and generates a new rewritten plan that evaluates the join between the employee and project tables remotely at the headquarters database. This final plan is of much better quality.
We compare the planning efficiency and plan quality of four query planners:
In this experiment we compare the behavior of Sage, DP, Initial, PbR-FI, and PbR-SD in a distributed query planning domain as the size of the queries increases. We generated a synthetic domain for the SIMS mediator and defined a set of conjunctive queries involving from 1 to 30 relations. The queries have one selection on an attribute of each table. Each information source contains two relations and can perform remote operations. Therefore, the optimal plans involve pushing operations to be evaluated remotely at the sources.
The results of this experiment are shown in Figure 31. Figure 31(a) shows the planning time, in a logarithmic scale, for Sage, DP, Initial, PbR-FI, and PbR-SD as the query size grows. The times for PbR include both the generation of all the random initial plans and their rewriting. The times for Initial are the average of the initial plan construction across all restarts of each query. Sage is able to solve queries involving up to 6 relations, but larger queries cannot be solved within its search limit of 200,000 partial-plan nodes. DP scales better than Sage, but cannot solve queries of more than 9 relations in the 1000 second time limit. Both configurations of PbR scale better than Sage and DP. The first-improvement search strategy of PbR-FI is faster than the steepest descent of PbR-SD.
Figure 31(b) shows the cost of the query plans for the five planners. The cost for Initial is the average of the initial plans across all the restarts of each query. The plan cost is an estimate of the query execution cost. A logarithmic scale is used because of the increasingly larger absolute values of the plan costs for our conjunctive chain queries and the very high cost of the initial plans. PbR rewrites the very poor quality plans generated by Initial into high-quality plans. Both PbR and DP produce better plans than Sage (in the range tractable for Sage) for this experiment. This happens because they are searching the larger space of bushy query trees and can take greater advantage of parallel execution plans. PbR produces plans of quality comparable to DP for its tractable range and beyond that range PbR scales gracefully. The two configurations of PbR produce plans of similar cost, though PbR-FI needed less planning time than PbR-SD. PbR-SD generates all the plans in the local neighborhood in order to select the cheapest one, but PbR-FI only generates a portion of the neighborhood since it chooses the first plan of a cheaper cost, so PbR-FI is faster in average. Figure 31 shows empirically that in this domain the locally optimal moves of steepest descent do not translate in final solutions of a better cost than those produced by the first-improvement strategy.