 Slide 1: Admin
Slide 1: Admin Slide 2: FPGA Technology Intro
Slide 2: FPGA Technology Intro Slide 3: Why Study Old FPGAs?
Slide 3: Why Study Old FPGAs? Slide 4: Xilinx 4000 Series CLB
Slide 4: Xilinx 4000 Series CLB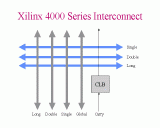 Slide 5: Xilinx 4000 Series Interconnect
Slide 5: Xilinx 4000 Series Interconnect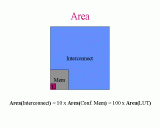 Slide 6: Area
Slide 6: Area Slide 7: FPGA CAD Flow
Slide 7: FPGA CAD Flow Slide 8: Synthesis
Slide 8: Synthesis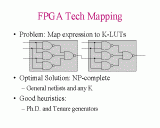 Slide 9: Tech Mapping
Slide 9: Tech Mapping Slide 10: Heterogeneous vs. Homogeneous
Slide 10: Heterogeneous vs. Homogeneous Slide 11: Hetero vs. Homo: Inside the cell
Slide 11: Hetero vs. Homo: Inside the cell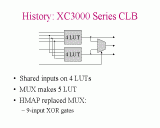 Slide 12: History
Slide 12: History Slide 13: Fast Carry Logic
Slide 13: Fast Carry Logic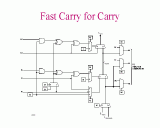 Slide 14: Fast Carry Logic
Slide 14: Fast Carry Logic Slide 15: Rent's Rule
Slide 15: Rent's Rule Slide 16: Speed
Slide 16: Speed Slide 17: Speed: The Event Horizon
Slide 17: Speed: The Event Horizon Slide 18: Speed: The Event Horizon
Slide 18: Speed: The Event Horizon Slide 19: Reprogrammibility
Slide 19: Reprogrammibility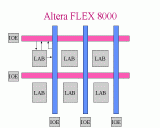 Slide 20: Altera FLEX 8000
Slide 20: Altera FLEX 8000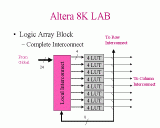 Slide 21: Altera FLEX 8000
Slide 21: Altera FLEX 8000 Slide 22: FastTrack Routing
Slide 22: FastTrack Routing Slide 23: FPGA Taxonomy
Slide 23: FPGA Taxonomy Slide 24: Programming Technology
Slide 24: Programming Technology- SRAM: SRAM takes up lots of space (5 or 6 transistors for 1 bit), but it can be reconfigured quickly and is generally very fast. Also, the config bits can be used as RAM in the design.
- Antifuse: This technology dosn't really have a place in reconfigurable computing because it is only one-time programmable. However, Antifuse-programmed connections are very fast, take up very little space, and don't load the line as much as transistor switches do.
- EEPROM: EEPROM is just as reconfigurable as SRAM, but it is very slow. It also does not lose its configuration when power is removed from the circuit.
- Flash: This technology can only be reliably reprogrammed a finite number of times. Its use in reconfigurable computing is probably limited. Like EEPROM, it does not lose its program when the power is turned off.
 Slide 25: Logic Cell Architecture
Slide 25: Logic Cell Architecture- The question we have to ask is "What is a good logic block
architecture?". Do we want a fine-grained structure or a coarse-grained one?
As a class, we came up with a big list of different possible things to put
inside a logic block.
- Look-up Tables
- PLA/PAL type structures
- Small DSP's
- Seas of Gates
- MUX's
- NAND Gates
- Pentiums
- The tradeoff here is between complexity and versatility. A fine-grained architecture like NAND gates offers a lot of versatility, but requires an enormous number of configuration bits. On the other hand, a coarse-grained array of Pentiums would require an enormous amount of interconnect resources. A balance has to be reached, but there isn't necessarily a solution that will be optimal for all applications.
 Slide 26: Summary
Slide 26: Summary- Architecture of Interconnect: Is the FPGA tiled, channeled, or
hierarchical? Or does it provide only local interconnect, like the CAL?
 Slide 27: Summary
Slide 27: Summary- All in all, one of the most important issues in FPGA technology right
now is the balance between homogeneity and heterogeneity. In general, CAD tools
deal with homogeneous structures much better than heterogeneous structures.
However, there is a push for more complex, heterogeneous structures because
they provide more speed and functionality. This is, of course, at the cost
of versatility and programmability.
- Xilinx's tiled interconnect structure dosn't obey Rent's rule. In general,
the number of I/O connections to a block of logic does not grow as fast as
the complexity of the logic. When the circuits get big, enough interconnect
won't always be available. Altera, on the other hand, has a hierarchical
interconnect scheme. The problem here is that because of load considerations,
not every logic block connects to every part of the interconnect. Small
changes in the HDL circuit description might provoke major changes to the
hardware layout.
- Class Discussion: A topic that comes up repeatedly in discussion is the concept of a module generator. If sophisiticated module generation tools can be made, synthesis tools can be taught to make use of heterogeneous FPGA features by looking for certain behavioral constructs in HDL descriptions of circuits.
Scribed by Andrew Mihal