We wrote a distributed, dynamically load-balanced, elastic, caching web server in MPI. The server system is capable of using an arbitrary number of machines, but tested on up to 10 machines in GHC 5205 it achieved linear speedup on a cache-friendly workload in its standard configuration.
A web server is a system that serves content to clients via HTTP. Like any other server, a web server must wait for an incoming request, parse the request, find the desired resource, then return that resource out to the requesting client. These resources can be anything, of any size, from small HTML files that are simply text, to massive video files, or the results of expensive computations. A generic web server must be able to robustly handle any of these.
In general, the pseudocode for a server looks like this:
init_server(); // Set up sockets, initialize cache, etc.
while(1)
{
connection = accept_connection(socket);
request = read_request(connection);
resource = parse_request(request);
serve_resource(resource, connection);
close(connection);
}
It is also important to note that web servers suffer heavy traffic--particularly as a web site becomes more popular. On its statistics page[1], Facebook notes that it experiences 526 million daily active users. If each of those users were to load their news feed only once per day, that is still a minimum highest-load of 6088 users loading their news feeds per second, with each load consisting of many HTTP requests. This is a clear motivation to parallelize--it is infeasible to have a server fulfill these requests serially, forcing users to wait on others before their feed can load. Requests come in parallel, so they should be serviced in parallel.
Luckily, web servers are conceptually very amenable to parallelism. Individual requests are generally completely data-parallel, in that they have no dependencies on other requests. From the standpoint of the client, there are dependencies (e.g., the HTML file for a page must be retrieved before any images on the page, since the HTML file defines which images need to be loaded), but the server does not care about them.
Additionally, there can be a bonus in terms of locality based on the structure of the web site a user visits. A very simple example can be seen on YouTube[2]. At the top-left corner of every page on YouTube is the YouTube logo. Every request to a page must include a request to this image, so it can be cached for better performance. This concept holds in general: if the design of a website ensures that some resources are accessed a lot of the time, then locality is achieved. This motivates the use of caching.
Another challenge to designing a parallel web server is that server traffic, while high, is also variable. Imagine an online shopping retailer serving the United States. Traffic on this site is going to be highest sometime where it is evening across the country, once people are back from their jobs. On the other hand, when it is late night or early morning, traffic will be low as most people are asleep. Since a web server must provision for the highest load, each day will result in wasted computational resources (e.g., electricity). This problem can be solved via elasticity, a concept in which resources are added or removed from the server system on-demand, based on the total load on the system. To make good use of elasticity, the server system should be distributed across multiple physical machines, so that an individual machine can be considered as a single computational resource to be added or removed.
Once we determined that we needed to distribute the server out to more than one machine, we knew that communication between machines would be one of our major challenges. Individual machines in the server system would need to be able to let other machines know about their status, so that the system could determine when to turn on a machine on or off. Additionally, the central machine to which all requests are directed would need to be able to determine which of the other machines in the system to have service the request.
Clearly, there is no potential for shared memory communication in a cluster
system. Thus, we decided to use MPI, which abstracts away the communication into
messages. As a very welcome bonus, it can also manage this communication across
multiple nodes, completely transparently to the programmer. The GHC 5205 cluster has
installed on it an implementation of MPI called OpenMPI[3], so we elected to build our server out of machines in that
cluster. We started with code from the tiny server[4] given as starter code in proxylab from 15-213.
Our system uses three classes of processes, called DISPATCHER,
BALANCER, and WORKER respectively. The
DISPATCHER is a single process that accepts all incoming requests to
the server. It then redirects the client to a chosen WORKER via an HTTP
307 redirect response (inspired by Cardellini, Colajanni, and Yu[5]). The client's redirected request is then serviced by the
WORKER. Meanwhile, the BALANCER, or just "Load balancer,"
is a single process that keeps track of the total load on each WORKER
node, and tells the DISPATCHER where to redirect incoming clients.

- A request comes in from a client to the
DISPATCHER - The
DISPATCHERredirects the request- An HTTP 307 redirect response is sent to the client, directing to the chosen
WORKER - A message is sent to the
BALANCERindicating that the chosenWORKERhas a new request
- An HTTP 307 redirect response is sent to the client, directing to the chosen
- The redirected request comes in
- The
WORKERservices the request, from cache if possible - The
WORKERtells theBALANCERthat it is done
Meanwhile, the balancer is in its own loop, receiving the messages being sent to it.

Each time the load balancer receives a message, it updates the relevant index of the array by incrementing or decrementing, depending on whether the message was an indication of a new request or of a request being fulfilled. It selects the worker with the fewest outstanding requests, and tells the dispatcher to begin redirecting there.
Negative values represent special states. -2 indicates that the associated process is either the dispatcher or the balancer itself. -1 indicates that the associated process is considered "off," and is an invalid redirect target.
Each time through its loop, the load balancer checks to see if the total number of outstanding requests is above a pre-defined threshold. If so, it selects the first "off" process and turns it on. This is done by sending the process a message. Similarly, if the number of outstanding requests is below another threshold, then it selects process with the fewest requests being serviced and sends it a message turning it off. Workers receive these messages, and if they are considered "off," then they sleep for a while before checking for any updates.
With this structure, the workload of the server is parallelized over requests, as each request is sent to an individual node of the cluster as it is received. For our evaluations and measurement, we ran the server with only one process per cluster node, to try and minimize the server's impact on others working in the cluster. The system can run with an arbitrary number of processes per node fully functionally--an array containing the host names mapped to each process would need to be changed to accommodate it, but no other changes would be necessary.
Although we have described our final design, we had several other ideas that we eventually discarded or optimized. The load balancer in particular underwent several iterations of design. One method we tried was to have the load balancer determine, out of n worker servers, which n/2 of them had the fewest outstanding requests. It would update the dispatcher with an array of these, and requests would be redirected to them in a round-robin fashion. Testing this showed that the server's performance was slightly worse than under the simpler, naive scheme, most likely since the load balancer was slower to update the dispatcher in the new scheme.
We also went through a few iterations of our cache design. Originally, we thought to have a single unified cache in the dispatcher, to avoid the extra network latency of redirecting off to a worker. This crippled our performance, as for each request, the server needed to parse the request, examine the cache for the result, and then either return the requested resource or redirect to a worker. Since the dispatcher is the major bottleneck in the system, slowing it down made it unable to handle many requests quickly. After deciding to have our worker servers manage their own individual caches, we had to determine what to cache. Eventually, we decided that it was worth it to cache everything, including requests for dynamic content--especially since the dynamic content is computationally expensive.
To handle testing, we wrote an automatic HTTP request generator. Given a list of files on the server, the tester randomly selects a file according to a probability distribution, requests it, then requests it again from the worker it is redirected to. It does this for as many files as it can across a period of time, outputting the total number of requests that were fulfilled across that time period. Since we want to measure how our server deals with load, it makes sense to stress the server over a given amount of time, using number of requests fulfilled as the performance metric.
This, too, we wrote in MPI. To make sure that elasticity was relevant, we ran the testing program in 48 processes over 12 machines in GHC 5205 (chosen from machines which were not also running the server). The total test time per process was 100 seconds, and we brought three processes online every 5 seconds. This gives us an amount of load that increases to a maximum, stays for a while, then decreases back to zero.
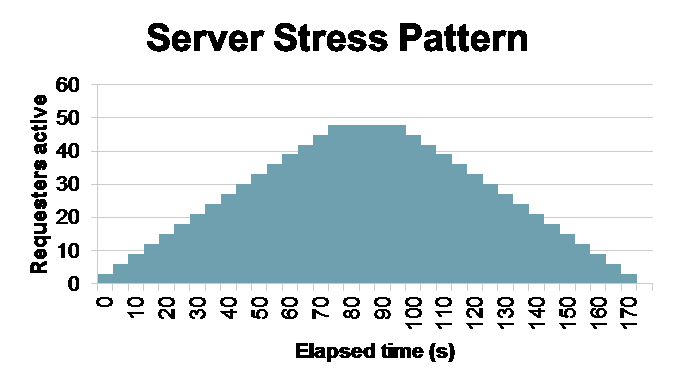
The important thing about the tester was that it must have been able to fully stress the server when the server is at its most powerful. If any node remained idle at peak load, then that would mean our throughput was limited by the tester itself, which would defeat the point of testing the server. We tested with so many requesters on so many machines for precisely this reason.
We developed two probability distributions for the tester to use. The first, which we call the "cache-friendly" workload, prefers to select from a small number of large files. This emphasizes the effects of a cache hit, and each individual file is more likely to be cached. The second, "cache-unfriendly" workload, prefers to select from a large number of small files, mitigating the usefulness of a cache hit and making cache misses more likely.
The actual files we used consist of a few HTML files, several images of various sizes, and three dynamic computations on strings. We generated three very long strings of Lorem Ipsum[6] text, and allowed for three computations on them: reversing the string, sorting the string by character, and recursively outputting the right half of the string. All of these were cacheable.
We tested the server on both of these workloads in three configurations. The first was our standard configuration, with all of the features enabled. The second was without elasticity, and the third was with elasticity and without caching. We ran the test on a number of worker servers from one to eight to determine performance increase.


Immediately important things to note:
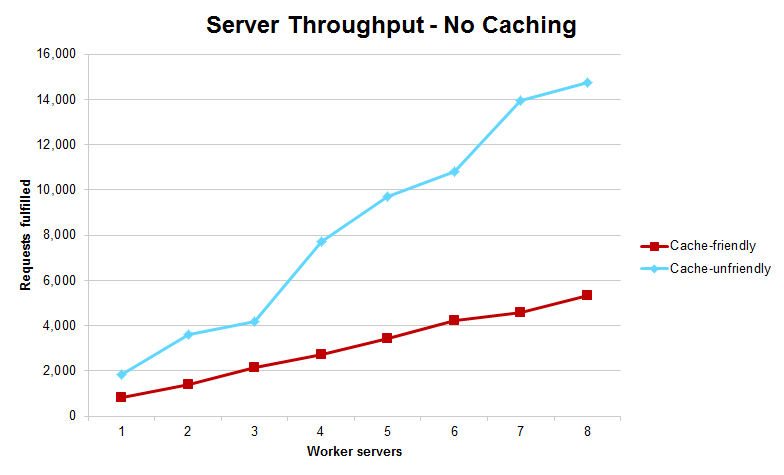
- Standard configuration, cache-friendly workload achieved linear speedup
- Standard configuration, cache-unfriendly workload dropped in performance at 8 workers
- No elasticity, cache-unfriendly workload achieved much better performance at 8 workers than with elasticity on
- The total number of requests fulfilled without caching dropped dramatically, and the cache-friendly workload fulfilled fewer requests than the cache-unfriendly workload
We were quite happy to achieve linear speedup in the standard configuration. Looking carefully at the graph, we can see that the total speedup is actually superlinear--but this is likely attributable to statistical fluctuations in how the files were selected and the amount of other work on the machine. Starting from four workers onward, the total number of extra requests fulfilled at each step was almost exactly the same--and about as much as what one worker server could do--so absent these fluctuations, we achieved linear speedup. Since requests are fully data-parallel, this makes sense, since the only inherently sequential part of our algorithm is in the dispatcher, which has a relatively unintensive job.
However, our cache-unfriendly workload performance actually dropped at eight workers. The only reason that performance should actually drop is if the workload balance worsens, since otherwise there are strictly more resources to use. The balance worsening must be the result of the load balancer. Either the load balancer's calculations begin to take too long on its array, or it is caught up in communication with the more workers. Our hypothesis, which we would have liked to test but did not have the time to, is that a cache-unfriendly workload on eight workers just barely skirted our elasticity thresholds, so servers were constantly being turned on or off, taking up valuable balance computation.
In the no elasticity graph, the eight workers point on the cache-unfriendly workload is significantly higher than the previous slope of the graph would suggest. Elasticity was the cause here. Compare the two graphs (elasticity on and off, cache-unfriendly), and they are very similar until eight workers. By turning elasticity off, we provided the server with more resources from the very start, so it was never stressed, and load balance was extremely good. Prior to this, however, elasticity did not have a performance hit at all, so for servers which need to consider resource usage, it is clearly worth it to implement.
The cache-friendly workload without elasticity is a bit harder to explain. The near non-improvement from three worker servers to four is offset by a massive improvement from four workers to five, bringing throughput up to what it was with elasticity on. We did not get the opportunity to try and test what might be the cause of this. It could be a statistical oddity, or perhaps someone was running an intensive computation on the fourth machine for that portion of the test. More tests of the configuration would very easily narrow down the cause, but we were limited on time.
The no caching graph is exactly as expected, however. Since our cache-friendly workload preferred larger files, if caching is turned off, then the amount of time to service each file would rise dramatically, reducing overall throughput drastically. The cache-unfriendly workload was not as affected, since it preferred smaller files. However, the total number of requests fulfilled did drop by a large amount, giving more confirmation that caching really is critical to performance. Even with these decreases in performance, the system still scaled linearly. The cache-unfriendly line is far from smooth, but since far fewer requests were actually serviced, this can be wholly attributed to statistical fluctuation.
That said, even though the system scales linearly, raw performance numbers could definitely be improved. Having the dispatcher use packet forwarding instead of HTTP redirection removes two steps from the anatomy of a request, but we were not familiar with how to do that and it is beyond the scope of the course. Smarter load balancing is always an option--we tried to find an algorithm based on average latency to serve a request, but the best we could come up with was too slow to be useable. Tweaking elasticity thresholds and cache parameters could also see improvements. An additional idea that would be the first thing we investigate coming back to this would be to network the workers' caches together. Particularly if the server started running multiple workers on the same machine, having a worker be able to investigate caches other than its own may be valuable. It could get rid of unnecessary disk accesses, and avoid expensive computations more than a single cache. And since all of the items on the server are (as of now) read-only, there is no problem with coherence that would necessitate implementing a costly cache coherence protocol.
Overall, our decisions in this project were sound. Distributing over multiple cluster nodes is an excellent way to scale a web server, due to the data-parallel nature of HTTP requests. Bottlenecking occurs only at the dispatcher, but for particularly large websites, using multiple dispatchers in different geographic areas is always an option. Elasticity is, without a doubt, worth the implementation difficulty in order to save costs, and caching was once again proven to be invaluable to a system's performance.
[1] Facebook
statistics
[2] YouTube
[3] OpenMPI
[4] O'Hallaron, David. Tiny Web Server
[5] Cardellini, Colajanni, and Yu. Dynamic Load Balancing on
Web-server Systems
[6] Lorem Ipsum
We worked on this together, from design to coding to bugfixing. Generally, we worked on the same thing at the same time, using our combined expertise to find errors in each other's logic and bounce ideas off of each other.
Woody found the tiny starter code, and the cache we used was
adapated from his cache that he used in his 15-213 proxylab. He also wrote a
significant part of the elasticity logic and the automatic request generator while
Eric was extremely busy with other classwork.
Eric presented the original idea, and was the primary source of design iteration. He handled all of the administrative work in the project, from managing the project website, to meeting with course staff. He also found most of the subtle bugs in the program, and wrote most of the code for serving dynamic content.