


Two sets of experiments were done using a linear search versus the algorithm we have outlined, one with randomly generated data and another using line and pad data from an actual PC board layout. One of the purposes for comparing against a linear search is that the big-O constant associated with a linear search is extremely small, helping to gauge how large our constant is. Timing analysis was done for both building the structure, either reading it in from file or randomly generating it, and for performing range queries.
The randomly generated data was created in such a way as to minimize the effect of the k term in the expected running time, by making  , the expected number of items found per query, be constant across experiments.
This was done by making the area rectangles were generated in proportional to the total number of rectangles to be generated.
The query rectangle for all of these runs was of fixed width and height.
The empirical results produced an
, the expected number of items found per query, be constant across experiments.
This was done by making the area rectangles were generated in proportional to the total number of rectangles to be generated.
The query rectangle for all of these runs was of fixed width and height.
The empirical results produced an 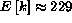 .
Table 1 shows a summary of results for several different total number of rectangles.
.
Table 1 shows a summary of results for several different total number of rectangles.

: Running times for both a simple linear algorithm and the algorithm outlined on both randomly generated data and for PC board design data. All times are measured in seconds.
The means and standard deviations for the build times come from 25 separate runs for each number of rectangles. The mean query times and standard deviations come from 15,500 queries spread across the 25 separate runs, measuring one average query time per run. The standard deviations were then computed from the 25 measures of average query time.
Our algorithm shows improvements in query time once you have reached approximately 4000 rectangles. Our build time is considerably higher and more variable, however even a moderate number of queries more than makes up for the excess build time. For example, in the case of 256,000 rectangles and 500 range queries performed, our total time for both building and querying is  seconds, while a linear search would take
seconds, while a linear search would take  seconds.
seconds.
The second set of tests was performed using the line and pad information from a PC board design, where the lines represent wires going between components and the pads are rectangular or circular regions where components are mounted to the board. Both the lines and pads were represented by their bounding rectangles. The design had a total of 2,260 pads and 10,718 lines, which were then represented as 12,978 rectangular regions. Again, a fixed width and height query rectangle was used. Ten runs for each method were done, in which the time to read the file and build the requisite data structures to perform searching were timed as a single process. Also, 1000 intersection queries were computed per run, and their total time measured. The last line of Table 1 shows the results.
In comparison to the randomly generated data of 16,000 rectangles, we appear to have an even greater speed edge using the PC board data.
The speedup in query time is a factor of ten better for our algorithm, and the build time is now only a factor of two slower.
The gap between the build times has decreased mainly because of the extra overhead added to both programs when reading in and converting the PC board data file.
Examining the improved query time speedup, this is partially accounted for by the  term for the two experiments.
For the randomly generated data,
term for the two experiments.
For the randomly generated data,  was found to be 229, while the PC board data had
was found to be 229, while the PC board data had  .
Another possible explanation for the improvement is that the PC Board tended to have a lot of small, non-overlapping rectangles, and relatively few rectangles that covered a lot of image area.
.
Another possible explanation for the improvement is that the PC Board tended to have a lot of small, non-overlapping rectangles, and relatively few rectangles that covered a lot of image area.