Write a small parsing system that can handle simple declarative sentences, simple NPs, and prepositional phrases, using simple semantic restrictions to block attachment of PPs that aren't licensed by a basic semantic lexicon.
The syntactic lexicon should contain lines with the following form:
("word" (feature value)+)
Look at the given syntactic lexicon for an example.
The syntactic lexicon should encode the following slots:
The value of the sem feature is a symbol corresponding
to the word's entry in the semantic lexicon. It is comprised of a
prefix (*A- for verbs, *O- for nouns), a symbol denoting the root form
of the word (e.g., SEE), and an index to differentiate the particular
meaning of the (root, pos) pair (positive integers, starting at
1). For example, to encode both the transitive and intransitive
meanings of "see", we would use *A-SEE-1 and *A-SEE-2).
The value of the semrole feature is a symbol
corresponding to the relation (slotname) denoted by the prepositions
in the semantic lexicon. It is comprised of a prefix (+) and the name
of the relation; e.g., for "in" we might encode the semantic role as
+LOCATION.
Since part of your assignment is to re-use the Tomita morphology
code and combine it with lexical lookup to inflect lexical entries for
number, you shouldn't have to include the number feature
unless you are encoding an irregular form not handled by the
morphology code (this piece of the assignment is described in more
detail later on).
The semantic lexicon should contain entries with the following form:
(frame-name (slot-name slot-value)+)
Look at the given semantic lexicon for an example.
The semantic lexicon should encode the following features:
Lexical concepts (those which appear in the sem
feature in the syntactic lexicon) are always prefixed with
*A- or *O-, and appear as the first element
in the semantic lexicon entries.
Inheritance (e.g., IS-A) links are always prefixed with '='. For
this assignment, you only need to include =IS-A. These
links appear inside the semantic lexicon entry as a list, where the
first element is =IS-A and the second element is the
parent class.
Classes are always prefixed with '&', and appear as fillers in
=IS-A or semantic role slots.
Semantic role names (semroles) are always prefixed with '+'. Semantic roles appear in semantic lexicon entries as lists, where the first element is the role name and the second element denotes the class restricting the set of legal fillers for the role.
You will need to write syntactic lexicon entries to handle the word occurrences in these sentences:
a man the man the men the boy the boys the man sees the man sees the boy the man sees the boy with the telescope the man sees the boy with the dog
You will need to write semantic lexicon entries to handle these concepts:
*A-SEE-1 *A-SEE-2 &O_ANIMATE *O-MAN-1 *O-BOY-1 *O-DOG-1 *O-TELESCOPE-1
You will need to encode these semantic roles:
*A-SEE-1, *A-SEE-2: (+INSTRUMENT &OPTICAL_INSTRUMENT) &O_ANIMATE: (+ACCOMPLICE &O_ANIMATE)
Your semantic frames should model this hierarchy fragment:
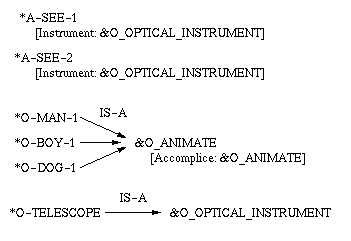
In the given code file, you will find
functions load-lexicon and load-semantics,
which you can use to load your completed lexicons into Lisp.
The grammar should include rules for the following constructions:
<start> <==> (<np>) <start> <==> (<vp>) <start> <==> (<np> <vp>) <np> <==> (<np> <pp>) <np> <==> (<det> <n>) <np> <==> (<n>) <vp> <==> (<vp> <pp>) <vp> <==> (<v> <np>) <vp> <==> (<v>) <pp> <==> (<p> <np>)
Your grammar should not use lexical rules inside the grammar; instead, you should use the Tomita "wildcard" rule syntax, and write a Lisp callout function to read in lexical items:
<n> <-- (%) <v> <-- (%) <det> <-- (%) <p> <-- (%)
The form of each rule should be like this:
(<n> <-- (%)
((x0 <= (parse-eng-word (string-downcase (symbol-name (x1 value)))))
((x0 cat) = n)))
You should write a function called parse-eng-word, which
performs morphology on its string argument, and returns the inflected
lexical f-structure for the word. This should be done in three
steps:
parse-eng-morph
to return the set of ("root" morph) pairs that are possible for the word;
inflect-lex to inflect nouns and verbs, as follows:
INFLECT-LEX
Assigns agreement features for N and V, depending on presence or
absence of +S morpheme and/or explicit lexical features:
N:
- Defaults to (PERSON 3), unless feature supplied by lexicon
- Defaults to (NUMBER SG), unless:
* feature supplied by lexicon
* +S is present -> (NUMBER PL)
V:
- If +S present, (PERSON 3), else will unify with any SUBJ
(functionally the same as (*OR* 1 2 3)
- Defaults to (NUMBER PL), unless:
* feature supplied by the lexicon
* +S is present -> (NUMBER SG)
load-lexicon function, so you
can retrieve the uninflected lexical items from the lexicon using
gethash).
You should use the compgra function to compile and
load the grammar (see the example in the given code file). You will need to
recompile your grammar with compgra each time you make a
change to the grammar before you will be able to test the change.
Once you have your grammar working, you should add Lisp callouts to the rules which attach PPs to NP and VP, in order to implement semantic restrictions.
The function semrole-filler-match, provided in the given code file, will do most of the work
for you -- its arguments are the semantic lexicon entry for the head
(NP or VP), the semrole (from the P's syntactic lexicon entry), and
the semantic lexicon entry for the filler (the PP object). This
function will return T or NIL depending on whether the semantic
lexicon contains information that licenses the given attachment, using
some inheritance methods defined in the function.
In order to use this function, you will have to write a grammar
callout, called license-attachment, which takes two
arguments: the f-structure for the head (NP or VP) and the f-structure
for the filler (PP), extracts appropriate information from the
f-structure(s) and/or the semantic lexicon, calls
semrole-filler-match, and returns the appropriate new
f-structure (head with PP attached) or NIL depending on the result of
the call to semrole-filler-match.
Your code for license-attachment should print a trace
message signalling the result of each call; see the examples
(mentioned below) for the format of the messages.
When you're all done, you should get outputs like those shown in
this set of examples, assuming you've got
all the parts right. (See the instructions on how to run the testing function, (run-tests).