Translingual Information Access
Language Technologies Institute
Carnegie Mellon University
5000 Forbes Ave. Pittsburgh PA 15213
ref@cs.cmu.edu
Abstract
We present an attempt at a coherent vision of an end-to-end
translingual information retrieval system. We begin by presenting a
sample of the broad range of possibilities. We then present an
overall workstation architecture, followed by two possible approaches to
the actual translingual IR stage presented in detail. Ranking
retrieved documents, query-relevant summarization, assimilation of retrieved
information, and system evaluation are all discussed in turn.
To be presented at
the 1997 AAAI Spring Symposium on Cross-Language Text and Speech Retrieval.
Introduction: Beyond Traditional Information Retrieval
Traditional information retrieval (IR) offers a suite of very useful
technologies, such as inverted key-word files, word-weighting methods
including TF-IDF, precision and recall metrics, vector-space document
modeling, relevance feedback, controlled-vocabulary indexing of text
collections, and so on.
Traditional IR technologies, however, have significant limitations,
among others the following:
Translingual Query, Retrieval, and Summarization
Let us first cast the problem of translingual IR (TIR) in its simplest
terms, and subsequently revisit the surrounding complexity. Assume a
query QS in the the user's language (definitionally, the
source language, SL). The central problem is to retrieve
relevant documents not just in the same source language, but also in
each target language of interest (TL1, TL2, ... TLk). Let
us start with a single target language. Let [DS] be a document
collection to be searched in the source language, and [DT] be
another document collection to be searched, but in the target
language. In order to search the [DS] with QS, all of the
standard IR techniques can be used directly (weighted key-words,
vector cosine similarity, latent semantic indexing (LSI), and so
forth). But none of these techniques apply directly to search
[DT] with QS. Possible approaches include:
Clearly, these methods increase in complexity, and the techniques
range from using statistical learning, to crude translation for
indexing, to precise conceptual analysis for both indexing and
translation. It seems to us that an appropriate research strategy is
to begin by protoyping the simpler methods, based on current technology.
If these yield good performance, then we plan to enhance the
prototypes and scale them up to usable systems for large-scale
applications.
If the simpler methods prove insufficient, we propose
to explore more complex and methods, rather than scaling up the
simpler methods.
To date, the LSI method has been investigated for cross-linguistic
query, starting with work at Bellcore by Landauer & Littman and later
Dumais, with partial success (Dumais et al. 1996). But the other methods
have not yet been investigated in any depth, nor have there been
many systematic cross-method comparisons. In addition to Davis &
Dunning's work (Davis & Dunning 1996),
we have recently performed an experiment
systematically comparing various methods (Carbonell et al. 1997). In
our experiments, a simpler technique related to LSI but without its
attempt at dimension reduction produced equivalent results at lower
processing cost: the Generalized Vector Space Model (GVSM).
Integrating Translingual IR into an Analyst's Workstation
In order for TIR to be used
successfully, it must be integrated into an environment with other
productivity tools, including the ability to produce at least a rough
translation of the retrieved documents, and the ability to handle the
ever-larger deluge of documents that will be retrieved when the
information sphere goes from English to all major languages.
We envision the following stages in translingual processing within
such an analyst's workstation:
These steps are illustrated in
Figure 1, and will be
described in the remainder of this paper, followed by a suggestion for
evaluating overall system performance.
We expect that a multi-stage design will be necessary in many actual
real-world applications, with fast but crude techniques
performing an intial filter before higher-quality but slower
techniques are applied.
Specific Translingual Information Retrieval techniques
Of the different methods for moving towards true TIR, two of the most
immediately practical are to exploit a parallel corpus with
(pseudo-)relevance-feedback or to apply knowledge-based methods to
translate the query.
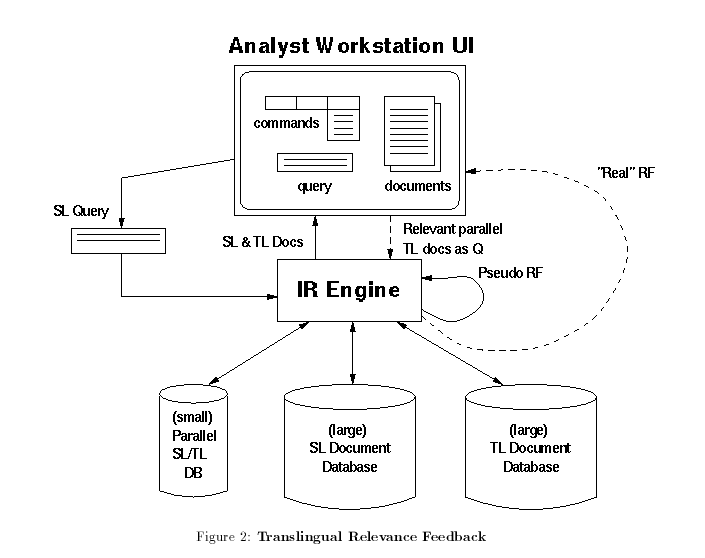
Translingual Relevance Feedback
If even a modest parallel corpus of documents can be located (or
created) for the source and target language pair, then we can exploit
the tried-and-true relevance feedback method to perform
translingual query, as outlined in Figure 2. The process
requires us to perform two queries, one on the parallel corpus to retrieve
SL/TL pairs by searching the SL side only with QT, and the other
to search the full pure-TL (and potentially much larger) document database
with the TL part of the retrieved documents as a query. Using the
Rocchio formula, we can improve on this pseudo-relevance feedback (RF)
process if the analyst is willing to provide relevance judgements for
the retrieved SL documents from the parallel corpus. With such
judgements, we can construct a better term-weighted query for the TL
search, essentially producing true translingual RF. Of course, this RF
process can also be used to enhance the SL query and search other SL
databases at no extra cost to or involvement from the analyst.
The envisioned mechanism is shown in Figure 2, and encompasses
the following steps:
- The analyst types in a source language query QS;
- Parallel corpus (source half) is searched by an IR engine using QS;
- One of the following methods is used to search the TL document database:
- If desired, the retrieved TL documents are summarized and/or translated for analyst inspection.
A major advantage of this method is that no translation at all needs to be
done in the early stages of information gathering, when the largest
volumes of information must be processed.
Knowledge-Based Methods for Translingual IR
When the translingual information retrieval is within a well-defined domain,
we expect that the infusion of knowledge-based techniques from the
fields of natural language processing (NLP) and machine translation
(MT) can provide the following benefits:
Query Expansion Translation:
When translating a query, it is not possible to
do a reliable exact translation, especially because queries tend
to include isolated words and phrases out of context, as well
as possibly full clauses or sentences. Any automated translation
risks selecting the wrong meaning of the query terms, and therefore
the wrong translation. Hence, we propose to perform an expansion
translation, in which all meanings of all query terms are generated,
properly weighed for base-line and co-occurrence statistics, so that
no meaning is lost. On a preliminary experiment using Lycos®,
this method yielded recall results comparable to a carefully hand
crafted target-language query, though at some degradation in
precision. One reason for this is that the documents themselves serve
as filters, since it is unlikely that a single document will hit one
sense of each term unless they are coherent sense-choices.
To the degree that we can enhance the query translation
by template extraction and deeper semantic analysis, as described
later in this section, we should be able to recover the loss in
precision.
Once the query is expanded/translated into QT, it is used
for retrieval, and the retrieved DT's can be summarized and/or
translated as discussed in following sections.
Linguistic Generalization:
Let's assume a scenario where the information gatherer wants to find
data related to mergers and acquisitions. He is immediately faced with
two issues for which NLP techniques provide assistance:
Linguistic Relations:
Linguistic generalization techniques like those sketched above can
help recall, but they do not necessarily help precision. In fact,
increasing the number of possible search terms increases the chance of
a false match due to random coincidence of terms. To make the most of
linguistic generalization, it is necessary to improve precision
through the use of linguistic relations.
The real cause of impreciseness in multiple keyword search is that all
information about the relationships between the words is lost. A
typical example is the noun phrase ``victims of teenage crime'', which
is likely to match documents describing ``teenage victims of crime''
in a keyword-style search. Only the loosest forms of linguistic
relation -- strict adjacency and/or near adjacency -- are typically
supported in current on-line search systems, and highly-frequent
function words (like the preposition ``of'') are often ignored. If it
were possible to parse each document and represent the linguistic
structure of the portions of text which seem to match the query, this
type of bad match could be ruled out. For example, a syntactic parse
results in different structures for the two ``victim'' sentences; if
matching during search included parsing and unification, these two
structures would not match, thus boosting precision.
Conceptual Querying:
The ultimate goal in retrieval is to match all the documents whose
contents are relevant, regardless of their surface form. Generalizing
the surface form (through morphological variation, category switch,
and synonym match) can help, but what if we want to retrieve documents
from multiple languages? We can extend the notion of a ``thesaurus''
for keyword synonyms to include terms from multiple languages, but
this becomes difficult to manage as the lexicon of search terms and
number of languages grows. Ideally, we would like to combine the
notion of linguistic generalization and linguistic relations into a
language-neutral query form which can be used to retrieve multilingual
documents.
The notion of conceptual querying for English is not new. The FERRET
system (Mauldin, 1991b) presented the idea of matching on the
conceptual structure of a text, rather than keywords, to improve
precision and recall. The TIPSTER/SHOGUN system (Jacobs, et al.,
1993), a large-scale elaboration of this theme, retrieved articles on
joint ventures and microelectronics through the use of template
matching, where the particular situations of interest (such as a
corporate takeover) were modelled via semantic frames whose heads
(called template activators) were the set of relevant terms
(e.g., the verbs ``buy'', ``acquire'', ``merge'', etc.) while their
slot fillers were the set of relevant object descriptors (e.g.,
company names, dates, numbers, units of currency, etc.).
The use of semantic relations to model meaning independent of surface
form has also been used in the machine translation field for
multilingual translation, in Knowledge-Based MT (KBMT). For example,
the KANT system (Mitamura et al., 1991) uses a conceptual form called
interlingua to model the linguistic relations among the source
terms in a deep semantic representation. The interlingua captures
domain actions, objects, properties, and relations in a manner which
is language-independent, and is used as an intermediate form during
translation.
We believe a synthesis of these approaches, referred to here as
conceptual query, can provide a convenient framework for the use of
linguistic generalization (to improve recall) and linguistic relations
(to improve precision), while also providing support for multilingual
search. The basic idea is embodied in these steps:
- The user specifies a query in his native language;
- The query is parsed into conceptual form, preserving relevant
linguistic relations in corresponding semantic slots (semantic
roles);
- All relevant surface generalizations (in the source language)
are compiled into a set of search templates, which contain all the
relevant morphologic variations, category switches, etc.;
- All relevant surface generalizations (in the supported target
languages) are compiled into a set of search templates, which contain
all the relevant morphologic variations, category switches, etc.;
- The templates are matched against the database, and relevant
documents are retrieved for the user. A rapid-deployment approach
which is under investigation involves the use of existing keyword
indices (e.g., Lycos) to locate potentially relevant texts, so that
the more computationally-intensive methods required for template
matching are focussed on a small subset of the entire database.
Ranking retrieved documents: Maximal Marginal Relevance
Searching any very large document data base, including the World Wide Web,
quickly leads to the realization that there are not just more
documents than anyone could ever assimilate, but also there are more
relevant documents than anyone could ever assimilate. Fortunately
there is a high degree of redundancy in the information content of
long lists of documents retrieved by IR engines. If only we could
reduce or eliminate this redundancy we would have a much more
manageable subset of relevant documents that nonetheless span the
information space. We created the MMR formula for
precisely this purpose: ranking documents both with respect to query
relevance and with respect to novelty of information content, where we
define the latter as non-redundancy, i.e. information not already
contained in previous documents already included in the ranked list
for the analyst's inspection. The MMR formula below gives a credit for
relevance and a penalty for redundancy, with a tunable parameter lambda
(where DB is the total document database, and RL the already produced
ranked list of documents):
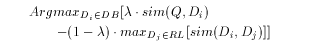
Summarization of Results
We envision the following framework for presenting multilingual search
results to the information gatherer:
- Based on the quality of the match to the query that was used to
retrieve each document, documents are scored and sorted using MMR;
- Documents scoring above a certain threshold are selected for
potential display to the user;
- A short summary is produced for each selected document, and that
summary is translated to the source (query) language;
- Information about each document (origin, language, score,
summary) is presented to the user in an interface which allows him to
select specific documents for additional processing (such as selective
assimilation, described below).
We are currently developing methods of automatically
creating summaries of documents. Unlike earlier work (Luhn 1958;
Paice 1990), we focus on generating query-relevant summaries
(Carbonell 1996), where a document will be summarized with respect to
the information need of the analyst, as expressed in his/or her query,
and possibly other available profile information.
Summarization is particularly useful for TIR because document access is
far faster if only the summaries of retrieved
target language documents need be translated, with further material
only translated upon drill-down requests.
(Translation is a much
more computation-intensive and time-consuming process than
summarization.)
Selective Assimilation of Results
Multi-Engine Machine Translation (MEMT) (Frederking and Nirenburg 94)
is designed for general purpose, human-aided MT.
The MEMT architecture is well-suited to the task of
selective assimilation of
retrieved documents.
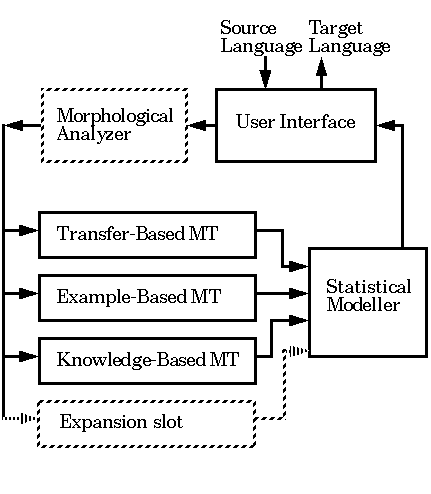
In the MEMT architecture,
shown in Figure 3, an input text is sent to several MT engines in
parallel, with each engine employing a different MT technology. Each
engine attempts to translate the entire input text, segmenting each
sentence in whatever manner is most appropriate for its technology,
and putting the resulting translated output segments into a shared
chart data structure after giving each segment a score indicating the
engine's internal assessment of the quality of the output segment.
These target language segments are indexed in the chart
based on the positions of the corresponding source
language segments. Thus the chart contains multiple, possibly
overlapping, alternative translations.
Since the scores produced by the engines are estimates of variable
accuracy, we use statistical language modelling techniques adapted
from speech recognition research to select the best set of outputs
that completely account for the source language input (Brown and
Frederking 95). These selection techniques attempt to produce the
best overall result, taking the probability of transitions between
segments into account as well as modifying the quality scores of
individual segments. In essence, we do Bayesian-style training to
maximize the probability of a correct translation given the available
options, their estimated quality, and the well-formedness of the
output translation as determined by a trigram language model. Thus
our MEMT techniques are an example of integrating statistical and
symbolic approaches; the MT engines that we have employed to date have
all been symbolic engines, while the integration of their outputs is
primarily statistical (Brown and Frederking 95).
The MEMT architecture makes it possible to
exploit the differences between MT technologies.
Differences in translation quality and domain size can be exploited
by merging the best results from different
engines. In the earlier Pangloss unrestricted translation system,
when Knowledge-Based MT (KBMT) could produce high-quality, in-domain translations,
its results were used; when Example-Based MT (EBMT) found a high-quality match, its results were used.
When neither of these engines produced a high-quality result, the wider-coverage
transfer-based engine supplied a lower-quality translation, which was
still much better than leaving the source language
untranslated.
As implemented in Pangloss, unchosen alternative
translations could be selected by the user through a special-purpose
interface that interacted with
the chart representation (Frederking et al. 93), which greatly increased the usefulness of the
transfer-based translations.
The application of this architecture to the current problem is clear.
Once
the user selects a translated summary for further investigation,
the selected document is translated by the MEMT system, with KBMT,
EBMT, transfer, and possibly
other MT engines combining to give the user an
initial, fully-automatic rough translation.
The user can examine the automatically translated document, and if the
document and situation warrant it, the user can proceed using
human-aided MT (HAMT) features as described above to quickly and easily
clean up the initial translation to produce a high-quality translation
of the document for dissemination, or incorporation with other analyses.
Evaluating System Performance
In order to evaluate the usefulness of more advanced techniques in a given
domain, experiments must be undertaken to measure the recall and
precision of existing methods (e.g., keyword search) vs. more
sophisticated techniques such as template
matching and partial template matching. For example, to measure the increase in
precision vs. processing time, one might plot one against the other in
a graph, to determine at one point diminishing returns make further
efforts unproductive. Since the more sophisticated symbolic
methods we are considering require both additional processing time (impacting
the user) and development time (impacting start-up cost), it is
important to determine whether the improvements in recall, precision,
and multilinguality are sufficient payoff.
In future work we will complete an initial implementation of the
conceptual search method, and evaluate its usefulness on a variety of
domains. Since large amounts of processing are currently required for
NLP and KBMT methods, it is likely
that at least in the initial implementation these will be useful mainly when used as a
batch process, or when applied to a text or domain that is already
pre-selected for relevance (example domains include on-line newsletters about a
particular topic of interest, daily flow in specialized newsgroups,
etc.).
Conclusion
We have attempted to present a coherent vision of a translingual
information retrieval system, illustrating the broad range of
possibilities with two specific examples. While we have already
conducted initial experiments in this area (Carbonell et al. 1997),
much experimentation
remains to be done, in order to see whether combinations of old
techniques or novel translingual techniques provide the necessary
performance to produce a useful translingual analyst's workstation.
References
Carbonell, J. G., 1996. ``Query-Relevant Document
Summarization''. CMU Technical Report, Carnegie Mellon University.
Carbonell, J., Yang, Y., Frederking, R.,
Brown, r., Geng, Y., Lee, D., 1997. ``A Realistic Evaluation of
Translingual Information Retrieval Methods'', submitted to SIGIR-97.
Davis, M., and Dunning, T., 1996. ``A TREC
evaluation of query translation methods for multi-lingual text
retrieval'', In Proceedings of the 4th Text Retrieval Conference
(TREC-4).
Dumais, S., Landauer, T. and Littman, M., 1996.
``Automatic Cross-Linguistic Information Retrieval using Latent
Semantic Indexing'', In Proceedings of SIGIR-96, Zurich.
Frederking, R., Grannes, D., Cousseau, P., and Nirenburg, S., 1993.
An MAT Tool and Its Effectiveness. In Proceedings of the DARPA Human
Language Technology Workshop, Princeton, NJ.
Frederking, R. and Nirenburg, S. 1994.
``Three Heads are Better than One.'' Proceedings of the fourth
Conference on Applied Natural Language Processing, ANLP-94, Stuttgart,
Germany.
Jacobs, P., Krupka, G., Rau, L., Mauldin, M. and
Kaufmann, T., 1992. ``Description of the TIPSTER/SHOGUN System as
used for MUC-4'', Proceedings of the Fourth Message Understanding
Conference, McLean, Virginia.
Luhn, H. P., 1958.``Automatic Creation of Literature
Abstracts'', IBM Journal, pp. 159-165.
Mauldin, M. L., 1991. ``Retrieval Performance in
FERRET: A Conceptual Information Retrieval System'', Proceedings of
the 14th International Conference on Research and Development in
Information Retrieval, Chicago.
Mitamura, T., E. Nyberg and
J. Carbonell. 1991. ``An Efficient Interlingua Translation System for
Multi-lingual Document Production.'' Proceedings of the Third Machine
Translation Summit, Washington, D.C.
Paice, C. D., 1990. ``Constructing Literature Abstracts
by Computer: Techniques and Prospects''. Information Processing
and Management, Vol. 26, pp. 171-186.
Salton, G. and McGill, M. J.,
1983. ``Introduction to Modern Information Retrieval'', (New York:
McGraw-Hill).
Salton, G., 1970. ``Automatic Processing of Foreign
Language Documents'', Journal of American Society for Information
Sciences, Vol. 21, pp. 187-194.
{kind=link}
{kind=link}