|
Random Protein-Protein
Interaction Prediction from Multiple sources |
|
|
One of the most important, but often ignored, parts of any clustering and classification algorithm is the computation of the similarity matrix. This is especially important when integrating high throughput biological data sources because of the high noise rates and the many missing values. In this paper we present a new method to compute such similarities for the task of classifying pairs of proteins as interacting or not. Our method uses direct and indirect information about interaction pairs to constructs a random forest (a collection of decision tress) from a training set. The resulting forest is used to determine the similarity between protein pairs and this similarity is used by a classification algorithm (a weighted kNN) to classify protein pairs. Testing the algorithm on yeast data indicates that it is able to improve coverage to 20% of interacting pairs with a false positive rate of 50%. These results compare favorably with all previously suggested methods for this task indicating the importance of robust similarity estimates.
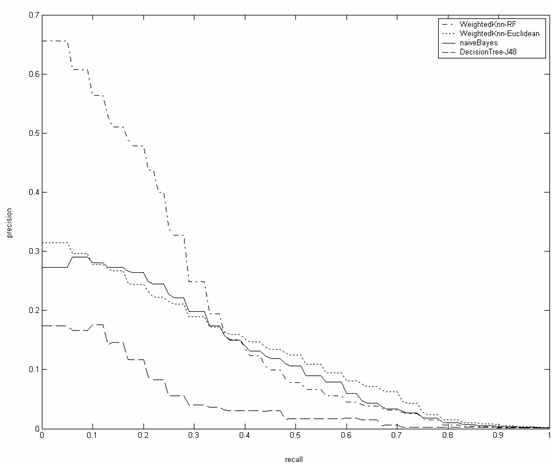
Figure 3.A Precision
.vs. Recall curves. Performance comparison of weightedkNN using random forest similarity, weightedkNN using Euclidean distance, naïveBayesand a
single decision tree(J48). See paper for discussion. |